High-Performance Large-Scale Image RecognitionWithout Normalization(2021, Deepmind) 2021년 2월의 Deepmind 에서 발표한 CNN 모델로, ImageNet에서 EfficientNet을 넘는 SOTA 성능을 달성하였다. 이는 기존의 Batch-Normalization 기법을 사용하지 않고 고성능을 달성한 Normalizer-Free Net 에 관한 내용으로, 논문의 내용을 살피고 요약해보자.
Abstract
‘배치 정규화(Batch-Normalization)’ 기법은 대부분의 이미지 분류 모델에서의 핵심 요소이지만 배치 크기(batch-size)에 대한 의존성, 예제(examples) 간의 상호작용으로 인해 완전한 성능을 보장하는 기 법은 아니다. 비록 최근 Deep ResNet 연구들에서 정규화 층(Normalization layer) 없이 학습 하는 것을 성공했지 만, 그 모델들은 배치 정규화를 사용한 best model의 정확도 성능에는 미치지 못하였고 큰 학습률 (learning-rate)값과 강력한 데이터 증식(data agumentation)에 대해서는 종종 불안정한 모습을 보여 왔다. 이번 연구에서 이러한 불안요소들을 극복한 AGC(Adaptive Gradient Clipping) 기법을 개발하고 크게 개선된 Normalizer-Free ResNets 클래스를 설계했다. 우리의 Smaller version 모델은 ImageNet에 대한 EfficientNet-B7의 정확도 성능을 넘고 8.7배 빠른 학습 속도를 보였으며 Largest version 모델은 top-1 정확도에 대해 SOTA(86.5%)를 달성하였다. 추가적으로 Normalizer-Free 모델은 3억 개의 label이 지정된 이미지 데이터셋에 대한 대규모 사전 학 습 후 ImageNet에서 미세조정할 때 배치 정규화 모델보다 훨씬 좋은 성능을 얻을 수 있었다.(89.2%)
Introduction
CV 분야에서 최신 모델들의 대부분은 배치 정규화를 활용한 ResNet 변형들이다. ResNet + Batch-Normalization 조합으로 연구자들은 훈련/테스트 셋에서 높은 정확도를 얻을 수 있 는 깊은 네트워크를 구축할 수 있게 됐다. 배치 정규화의 장점은 여러 가지가 있지만 현 작성글에서는 생략한다. 하지만 배치 정규화에도 불이익이 존재한다.
1. memory overhead를 유발하고 일부 네트워크에서 기울기(gradient)를 평가하는 데 필요한 시간 을 증가시키는 고비용의 기법이다.
2. 조정해야 할 숨겨진 하이퍼 파라미터(hidden hyper parameters)를 도입하여 훈련 중과 추론 시 모델의 동작 사이에 불일치를 발생시킨다. 즉, 미세조정이 필요한 다른 하이퍼 파라미터를 필요로 하게 된다는 의미이다.
3. 미니 배치에서 훈련 예제 간의 독립성을 깨뜨린다. 배치 정규화 네트워크가 다른 하드웨어에서 정확하게 복제하기 어려운 경우가 많으며 배치 정 규화로 인해 분산 학습에서 구현 오류를 일으키는 원인이 될 수 있다.
4. 배치 정규화의 성능은 배치 크기에 민감하며 해당 네트워크는 배치 크기가 작을 때 성능이 좋지 않 아, 모델의 크기가 하드웨어 성능에 좌지우지될 우려가 있다.
위의 단점들로 인해 배치 정규화 기법이 좋더라도 추후를 생각하면 다른 대안을 찾을 필요가 있었는데, 운이 좋게도 앞서 연구자들이 배치 정규화 없이도 학습을 하는 시도를 해왔다.
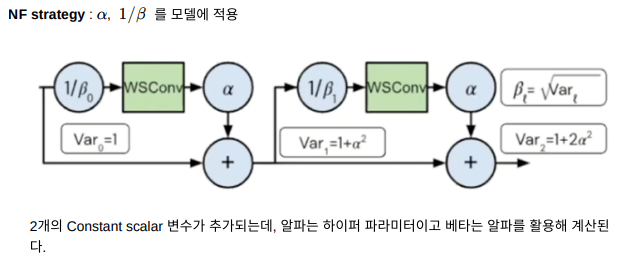
Brock et al. 은 Normalizer-Free ResNets을 공개하면서 초기화 시 residual branch를 억제하고 Scaled Weight Standardization을 적용하여 mean-shift를 제거하는 방식을 보여주었다.
이러한 시도들의 핵심은 residual branch 에서 hidden activation의 크기를 억제함으로써 정규화 없이 도 매우 깊은 ResNet 학습이 가능하다는 점이다.
- residual block : 일련의 잔차 연결(skip connection) 과정이 일어나는 multi layers
- residual branch : 잔차 연결 과정에 속한 각각의 layer
우리는 배치 정규화 없이 현 SOTA 모델인 EfficientNet의 성능을 넘기 위해 다음과 같이 작업했다.
1. ‘unit-wise ratio of gradient norms ro parameter norms’ 에 따라 기울기를 clip(자르는)하는 Adaptive Gradient Clipping(AGC) 기법을 제안하고 해당 기법이 정규화 없는 네트워크를 거대한 배치 크기 및 데이터 증식을 갖고도 학습이 이뤄지게 할 것임을 증명할 예정이다.
2. ‘NFNets’ 라는 정규화 없는 ResNets 무리를 만들어 SOTA를 넘는 정확도와 빠른 학습 속도를 확 보할 것이다. 이후 NFNet로부터 얻을 수 있는 이점들을 설명하지만 이 역시 생략한다.
Understanding Batch Normalization
배치 정규화를 제거하기 위해서는 우선 ‘배치 정규화(Batch-Normalization’가 무엇인지, 이점이 무엇 인지 알 필요가 있다.
1. Batch Normalization downscale the residual branch
skip connection & batch normalization의 결합은 우리가 모델에서 수 천개의 층을 쌓을 수 있게 해준 요소이다. 이러한 특징은 배치 정규화가 residual branch에 배치될 때 초기화 시 잔차 분기에 hidden activation 크기를 줄임으로써 발생한다. 이를 통해 signal이 skip path로 편향되어 학습 초기에 네트워크가 잘 작동하는 기울기를 갖도록 하여 효율적인 최적화를 가능하게 해준다.
2. Batch Normalization eliminates mean-shift
ReLu, GeLu 같이 대칭이 아닌(not anti-symmentric)(=비대칭) 활성화 함수는 0이 아닌 평균 활 성화(non-zero mean activation)를 가진다. 이러한 함수들로 인해 네트워크 깊이가 증가함에 따라 모델이 복잡해지고 깊이에 비례하는 임의의 단일 채널에서 다양한 학습 예제 활성화의 ‘mean-shift’ 를 도입함으로써 네트워크 초기화 시 모 든 학습 예제에 대해 동일한 label을 예측할 수 있게 된다. 이를 통해 배치 정규화는 각 채널의 평균 활성화가 현재 배치에서 0이 되도록 하여 mean-shift를 제거한다.
3. Batch Normalization has a regualrizing effect
배치 정규화는 학습 데이터의 부분 집합에서 계산되는 배치 통계에서의 noise로 인해 정확도를 강 화하는 ‘regualrizer(정규화)’로 동작한다고 믿어진다. 배치 정규화 네트워크의 테스트 정확도는 종종 배치 크기를 조정하거나 분산 학습에서 ghost batch normalization을 사용하여 향상될 수 있다.
4. Batch Normalization allows efficient large-batch training
배치 정규화는 손실 환경(loss landscape)을 부드럽게 하여 최대로 안정적인 learning-rate를 확 보할 수 있다. 손실 환경(loss landscape) : 파라미터에 따른 손실 값(loss)의 변화 혹은 증감 해당 관점은 배치 크기가 작을 때 이점이 없지만, 누군가 커다란 배치 크기와 같이 효율적으로 학습 하기를 원한다면 큰 학습률에서의 학습 능력은 필수적임을 보인다. 대규모 배치 학습은 고정된 epoch 값 내에서 더 높은 정확도를 달성하지는 않지만 더 적은 parameter 업데이트로 정확도를 얻을 수 있으므로, 다수의 devices에서 병렬화 될 때 학습 속도 가 크게 향상한다.
Towards Removing Batch Normalization
많은 학자들은 앞서 설명한 정규화의 이점들을 복구함으로써 정규화 없이 고성능의 ResNet 학습을 시 도해왔다.
이러한 시도들의 대부분은 작은 상수 혹은 learnable scalars를 도입하여 초기화 시 residual branch 의 활성화 규모를 억제한다.
하지만 이러한 방법으로는 기존 성능을 따라잡는데 한계를 느꼈으며, ‘Normalizer-Free ResNets(NF-ResNets)’를 개발하고자 했다.
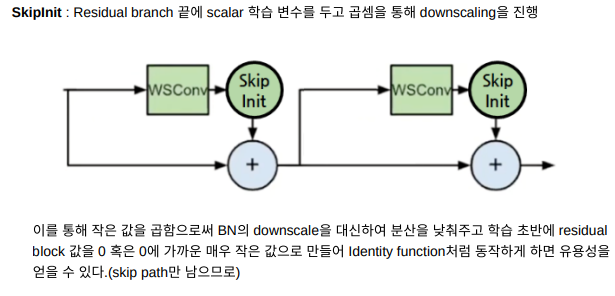
Brock et al. 에서 각 residual branch 끝 부분에 0으로 초기화된 learable scalar(학습 가능한 상수)를 포함하는 것이 유익하다는 것을 발견했다. ⇒ SkipInit 기법
Brock et al. 이 제시한 'Scaled Weight Standardization' 을 적용하였고 Dropout, Stochastic Depth 기 법을 추가로 적용하여 과적합을 방지하고 연산량 감소 효과를 불 수 있었다.
- Weight Standardzation(WS) : 기존 BN이 갖고 있던 단점을 보완하며 성능을 올리기 위해 고안 된 normalization 기법으로, 기존 기법들은 feature activation을 대상으로 정규화가 진행되는 반 면, WS는 weight(convolution filter)를 대상으로 정규화를 수행한다.
- Stochastic Depth : Dropout으로부터 고안된 기법으로, train 중 layer의 부분을 무작위로 dropout 함으로써 depth를 줄이고 연산 복잡도를 낮추되, test 할 때는 다시 layer 상태를 원복한 다.
추가적인 기법들을 통해 NF-ResNets는 배치 크기가 1024인 ImageNet의 배치 정규화 + 사전 활성화 된 ResNet이 달성한 정확도에 도달했으며 배치 크기가 매우 작은 경우에는 배치 정규화된 모델을 훨 씬 능가했다.
그러나 대형 크기의 배치일 경우(4096 이상), 배치 정규화된 네트워크보다 안 좋은 성능을 보이며 EfficientNet의 성능에는 미치지 못하였다.
Adaptive Gradient Clipping for Efficient LargeBatch Training
NF- ResNets를 더 큰 배치 크기로 확장하기 위해 다양한 gradient clipping 전략을 탐색했다.
‘Gradient Clipping’은 학습을 안정화하기 위해 LM(Language Model)에 종종 사용되며, 최근 고성 능 NF-ResNets와 gradient descent에 비해 더욱 큰 학습률로 학습이 가능하다.
- Gradient Clipping : 기울기를 자르는 기법으로, 기울기 소실 및 폭발을 막기 위해 임계값 (threshold / lambda)을 넘지 않도록 자르는(감소시키는) 기법
최적의 학습률은 가장 안정적인 학습률에 의해 제한되므로, 해당 기법은 조건이 좋지 않은 손실 환경 혹은 큰 배치 크기로 학습할 때 특히 중요하다.
[norm 수식 테스트]
Ablations for Adaptive Gradient Clipping (AGC)
AGC 효과를 테스트 하기 위해 다양한 환경으로 구축을 시도했다.
ImageNet 에서 NF-ResNets-50 및 -200 모델에 대한 사전 실험을 진행했으며 256~4096 사이의 배 치 크기 범위에서 Nesterov momentum과 함께 SGD를 사용하여 90 epoch 동안 학습을 진행했다.
- SGD의 단점인 parameter의 불안한 변경 폭 및 느린 학습 속도로 인해 학습 속도와 운동량을 조절 하는 optimizer가 등장하였는데, 이 중 ‘Adam’, ‘Momentum’ 등등이 이에 해당한다.
- learning_rate : 최적화의 속도를 조절하는 변수로, 너무 작으면 수렴까지 시간이 오래 걸리고 너 무 크면 학습 진행이 되지 않는다.
- learning_rate decay : 학습률 감소, 초반에는 큰 폭으로 이동하여 빠르게 내려가고 점점 학습률을 줄여 조심스레 움직이는 변수이다. (평지보다 내리막길에서 조심스레 내려가는 사람의 걸음 속도 를 생각해보면 된다.)
- Momentum : 진행 속도에 관성을 부여하여 saddle point & local minima 에 빠지더라도 그 지점 을 벗어나며 부드럽게 곡선 형태로 이동하게 해주는 변수이지만, 관성으로 인해 오히려 수렴 지점 을 벗어나는 경우가 생길 수도 있다.(overshooting issue)
- Nesterov Momentum : 관성을 똑같이 주지만 현재 속도로 한 걸음 미리 가봄으로써 overshooting 된 만큼 값을 차감하여 진행 속도를 교정한다.
추가적으로 의 범위를 [0.01, 0.02, 0.04, 0.08, 0.16] 으로 변경해가며 테스트를 진행하였고, 우리는 큰 배치 크기에서의 안정성을 위해서는 clipping threshold가 작을수록 유용할 것임을 발견했다
Normalizer-Free Architectures with Improved Accuracy and Training Speed
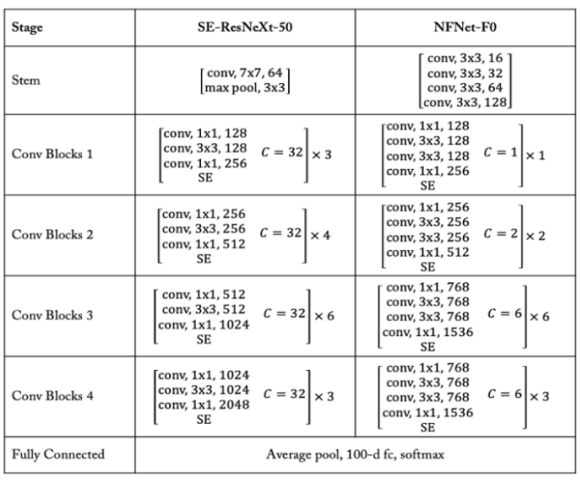
현재 이미지 분류에서 일반적인 SOTA 모델은 neural architecture search에서 파생된 모델 확장 전략 (scaling strategy)과 backbone으로 bottleneck blocks의 변형을 기반으로 한 EfficientNet 모델들이 다. 우리는 GeLu 활성화 함수가 포함된 SE-ResNetXt-D 모델이 훌륭한 baseline으로 판단, 이를 활용하 여 테스트를 진행하기로 했다.
<SE-ResNeXt-50 vs NFNet 구조 비교>
진행에 앞서 우리는 다음과 같은 변경점을 적용하기로 했다.
1. Block width에 관계없이 3x3 conv에서 group width(각 output unit이 연결된 채널 수)를 128로 설정했다.
2. backbone 모델에 두 가지 변화를 주었다.
a. ‘default depth scaling pattern’(ResNet-50에서 101 혹은 200까지 depth를 구축하기 위해 사용했던 방식)은 2,3 번째 stage에서 불균일하게 layer의 수를 증가시키며 이때 1,4 번째 stage의 3 blocks는 유지하도록 한다.
여기서 ‘stage’는 activation의 width, resolution(해상도)이 동일한 residual blocks의 시퀀스 를 의미한다.
앞쪽 stage에서 과도하게 소모 자원을 줄이게 되면 고품질의 features를 추출하는데 용량이 충분치 않다.
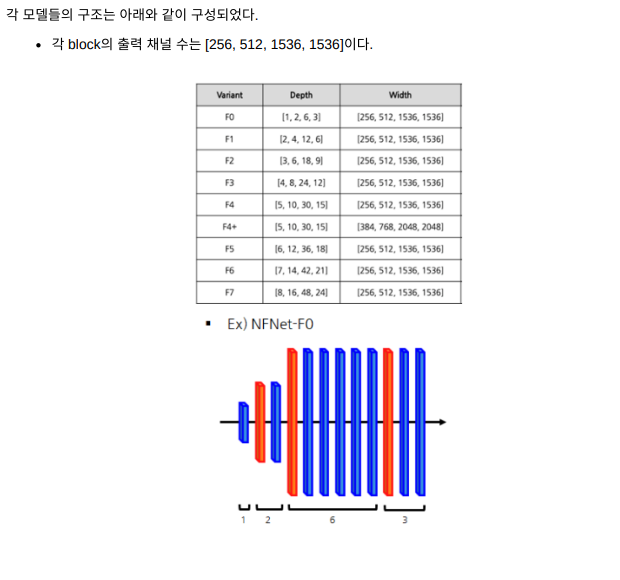
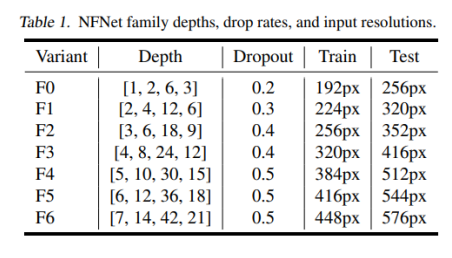
이를 염두하며 가장 작은 모델 버전인 F0 를 만들었는데, 이는 간단한 패턴인 [1,2,6,3]을 적용 하기 전에 만든 모델이다.
여기서 [1,2,6,3] 은 얼마나 많은 bottleneck blocks를 각 stage에 할당할 수 있는 지를 나타내 는 변수이다.
b. 우리는 [256,512,1024,2048]과 같이 stage가 256개 채널로 시작해서 매 stage마다 두 배씩 증가하는 ResNet의 default width pattern을 재고려했고 결국 가장 좋은 단 하나의 width pattern을 선정했는데, 바로 [256, 512, 1536, 1536] 이다.
해당 패턴은 3번째 stage에서 용량을 늘리고 4번째 stage에서는 용량을 약간 줄여 훈련 속도 를 어느정도 일정하게 유지하도록 설계됐다.
ResNet의 기본 구조와 우리가 고른 depth pattern에서 3번째 stage가 용량을 추가하기 좋은 위치라는 경향이 있음을 발견했는데, 이는 해당 stage가 큰 용량을 가질 만큼 충분히 깊고 마 지막 stage보다 좀 더 높은 해상도(resolution)를 가지면서 feature hierarchy를 더 깊게 접근 할 수 있었기 때문이었다.
그리고 우리는 residual block 자체의 구조를 다시 생각해보았다.
다양하고 참신한 변화를 생각했지만 1번째 stage 이후에 비선형성을 동반한 3x3 grouped conv를 추 가하는 것이 가장 좋은 개선점으로 결론지었다.
마지막으로, 다양한 compute budget으로 모델 변형을 생성하기 위한 scaling strategy를 수립한다. EfficientNet의 scaling strategy는 모델의 depth, width, input resolution을 같이 스케일링 하는 것으 로, MobileNet과 같은 매우 슬림한 backbone이 있는 base model에 적합하다.
그러나 우리는 위에서 언급한 width pattern, scaling depth 및 각 변형이 이전 모델보다 학습 속도의 약 절반이 되도록 scaling training resolution을 사용하는 전략을 적용하기로 했다.
우리가 학습하는 것보다 좀 더 높은 해상도에서 추론하여 이미지를 평가하였고 각 변형에 대해 학습 시 의 해상도보다 약 33% 더 큰 것으로 선택됐다. 이때 해당 고해상도에서는 fine-tune 은 진행하지 않았다.
그리고 모델 용량이 증가함에 따라 정규화 강도를 높이는 것이 도움이 됨을 발견했다. 그러나 weight decay(가중치 감쇠) 혹은 stochastic depth rate(확률적 깊이 비율? 속도?) 를 수정하 는 것이 효과적이지 않아, 대신 Dropout의 drop rate를 조정했다.
해당 과정은 우리 모델이 배치 정규화의 implict regularization이 부족하고 explicit regularization이 없으면 극적으로 과적합 되는 경향이 있기 때문에 특히 더 중요하다.
Summary & Model Architecture
요약하자면, 해당 논문 모델의 주요 특징은 다음과 같다.
1. Brock et al.이 제시한 Normalizer-Free 설정을 수정된 width & depth patterns와 두 번째 Conv2d layer와 같이 SE-ResNetXt-D 모델에 적용하였다.
2. classifier layer의 linear 가중치를 제외한 모든 매개변수(parameter)에 AGC를 적용하였다.
3. 배치 크기 1024~4096 구간에서 = 0.01로 설정하였다.
논문에서는 BN의 이점들을 설명했지만 다음과 같은 구성을 통해 BN을 제거하고도 장점을 보완할 수 있다 고 여겼다.
1. Downscales the residual branch ⇒ SkipInit or NF Strategy
Adaptive Gradient Clipping(AGC): 위 3가지 특징으로 BN을 보완해보려 했지만 2048 batch_size 이상에서 성능이 떨어짐을 확인했다.
저자들은 대규모 LM 학습 시 사용된 GC(Gradient Clipping) 기법을 적용하고자 했으며, 좀 더 유용한 성 능을 위해 Adaptive 하게 변경했다.
class AGC(optim.Optimizer):
def __init__(self, params, optim: optim.Optimizer, clipping: float = 1e-2, eps: float = 1e-3, model=None, ignore_agc=["fc"]):
if clipping < 0.0:
raise ValueError("Invalid clipping value: {}".format(clipping))
if eps < 0.0:
raise ValueError("Invalid eps value: {}".format(eps))
self.optim = optim
# 입력받은 optim 정보에 clipping, eps 인자를 추가
defaults = dict(clipping=clipping, eps=eps)
defaults = {**defaults, **optim.defaults}
# 논문에서는 fc layer에 agc를 적용하지 않았다고 명시
if not isinstance(ignore_agc, Iterable):
ignore_agc = [ignore_agc]
if model is not None:
assert ignore_agc not in [
None, []], "You must specify ignore_agc for AGC to ignore fc-like(or other) layers"
names = [name for name, module in model.named_modules()]
for module_name in ignore_agc:
if module_name not in names:
raise ModuleNotFoundError(
"Module name {} not found in the model".format(module_name))
params = [{"params": list(module.parameters())} for name,
module in model.named_modules() if name not in ignore_agc]
else:
params = [{"params": params}]
...
...
@torch.no_grad()
def step(self, closure=None):
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.agc_params:
for p in group['params']:
if p.grad is None:
continue
param_norm = torch.max(unitwise_norm(
p.detach()), torch.tensor(self.eps).to(p.device))
grad_norm = unitwise_norm(p.grad.detach())
max_norm = param_norm * self.clipping
trigger = grad_norm > max_norm
clipped_grad = p.grad * \
(max_norm / torch.max(grad_norm,
torch.tensor(1e-6).to(grad_norm.device)))
p.grad.detach().data.copy_(torch.where(trigger, clipped_grad, p.grad))
return self.optim.step(closure)
def unitwise_norm(x: torch.Tensor):
if x.ndim <= 1:
dim = 0
keepdim = False
elif x.ndim in [2, 3]:
dim = 0
keepdim = True
elif x.ndim == 4:
dim = [1, 2, 3]
keepdim = True
else:
raise ValueError('Wrong input dimensions')
return torch.sum(x**2, dim=dim, keepdim=keepdim) ** 0.5
여기서 stem은 여러 Conv layers로 구성된 국소 특징을 추출하는 부분으로, 3x3 크기의 커널(kernel) Conv layer가 4개 사용되었으며 각각의 stride와 out_channels는 [2,1,1,2], [16,32,64,128] 를 따른다. 이를 통해 입력 이미지의 1/4 크기에 해당하는 128 channels feature map을 얻을 수 있고 마지막 Conv layer 외에는 GeLu 활성화 함수가 적용된다.
stage1~4는 위 Table1 그림을 보면 알 수 있듯이, [N, 2N, 6N, 3N] 개수 만큼의 개별 block으로 구성된 메 인 모듈이다.
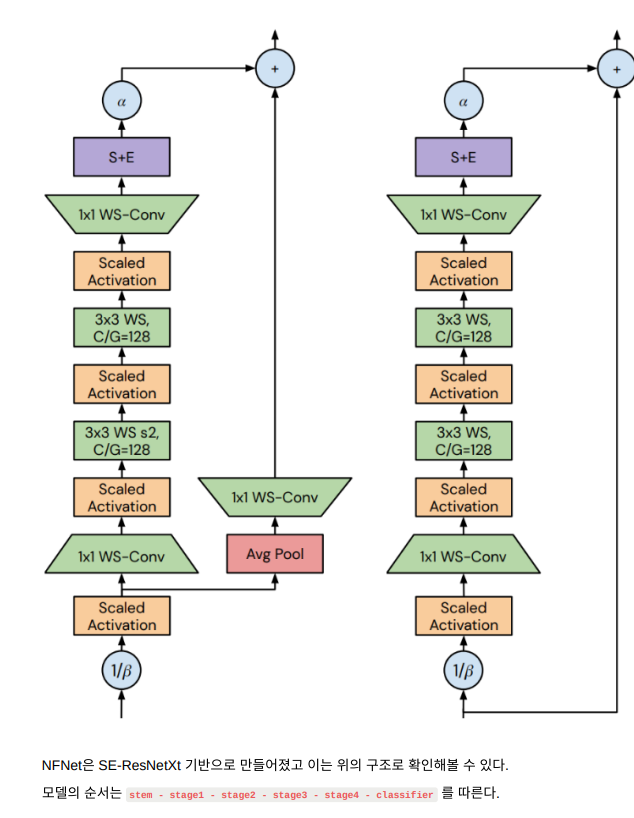
모델의 용량을 제어하는 stage 2,3,4의 각 첫 부분을 transition block 이라 하며 feature map의 사이즈를 1/2로 수축시키는 조작이 가해지고(위 그림 좌측 구조) 그 외의 blocks 부분은 기본적으로 위 그림 우측 구 조(Non-trasition block)를 따른다.
block의 첫 1x1 Conv 에서의 채널 수는 출력 채널 수(out_channels)의 1/2가 되고, 이후 2개의 3x3 Conv에서는 128 채널을 한 개의 group으로 하는 Grouped Conv가 적용된다. 뒤 이어 1x1 Conv에 의해 출력의 채널 수를 맞춰준다.
모든 blocks은 bottleneck 안에 ResNet bottleneck 에 3x3 grouped Conv를 추가한 pattern을 적용했는 데 이는 main path가 아래의 구조로 구성되었음을 의미한다.
- 1x1 Conv(output_channels이 해당 block의 output_channels 1/2 값에 해당하는) - group width가 128인 두 개의 3x3 grouped Conv (그림의 C/G 는 Grouped Conv에서 그룹 당 채널 수가 128로 고정되었음을 의미한다.) - 마지막(final) 1x1 Conv(output_channels이 해당 block의 output_channels 와 동일한)
각 block의 끝에는 globally average pools를 적용한 Squeeze & Excite(SE) layer가 이어진다.
모든 residual stages가 끝난 후, 저자는 channels 수를 두 배 증식하는(EfficientNet의 final expansion conv와 유사하게) 1x1 expansion Conv 를 적용 후 global average pool 을 넣었다.
이 layer는 매우 얇은 네트워크를 사용할 때 주로 유용하지만 backbone 을 기반으로 매우 얇은 네트워크 를 학습하려는 향후 작업에 도움이 되도록 더 넓은 네트워크에 유지(retain)시켰다.
저자는 이런 Conv layer 를 average pooling 이후에 FC layer로 변환하고자 했지만 효과가 없는 것으로 판단했다.
Scaled Activation layer 를 통해 출력의 분산을 1로 유지한다.
모든 Conv layers는 standardized weight에 학습 가능한 affine(아핀) gain 을 적용하고 convolution 연 산의 출력에 학습 가능한 affine bias 를 적용하는 Scaled Weight Stadardization 를 적용했다.
weight decay 는 affine gain, bias, SkipInit gain 중 어디에도 적용되지 않았다.
SE layer는 그들의 FC layer 및 FC의 classifier layer 내 가중치에 WS 를 적용하지 않았다.
LeCun initialization(LeCun 논문 기법) 을 사용하여 이러한 layer의 기본 가중치를 초기화 한다.















댓글