
논문: https://arxiv.org/abs/1809.00219
ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks
The Super-Resolution Generative Adversarial Network (SRGAN) is a seminal work that is capable of generating realistic textures during single image super-resolution. However, the hallucinated details are often accompanied with unpleasant artifacts. To furth
arxiv.org
ESRGAN은 Enhanced Super-Resolution Generative Adversarial Networks로 SRGAN에 Enhanced가 더해진 의미이다.
서론
SRGAN은 고해상도의 이미지를 만들 때, 현실적인 질감으로 만들어 내기도 하지만, 인공적인 디테일도 만들어 내기도 한다는 단점이 있다.
위의 장점을 더욱 살리고 단점을 상쇄하기 위해 총 3가지의 기본 요소를 연구하여 새로운 ESRGAN 모델을 제안했다.
1) SRGAN 네트워크 구조
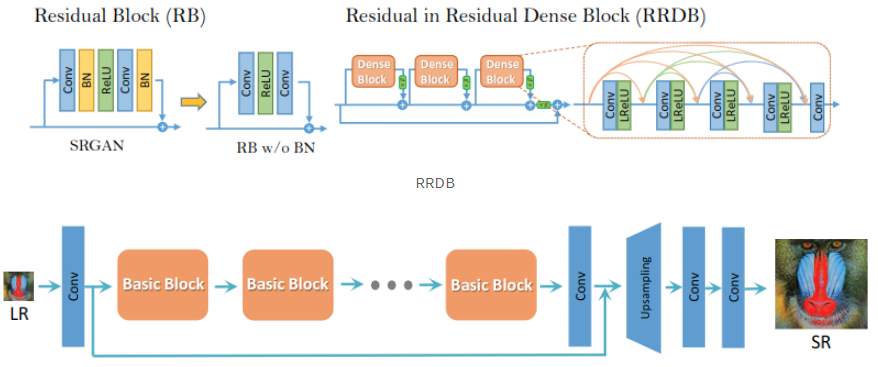
- 기존 SRGAN의 Batch Normalization을 없애고 Residual in Residual Dense Block(RRDB)을 도입
\
SRGAN에서는 Batch Normalization(BN)을 사용하지만, train 데이터셋과 test 데이터셋의 통계치가 달라 BN을 사용하면 artifact 현상이 생기게 되며, 일반화 성능이 저하되빈다. 따라서 저자들은 안정적인 학습과 일관된 성능을 위해 BN을 제거하였습니다. BN을 제거함으로 계산 복잡도, 메모리 사용량에서 이점이 생겼습니다.
기존의 SRGAN의 구조는 그대로 사용하며 Block만 교체한 모습이며, RRDB는 기존 SRGAN의 Residual Block 보다 더 깊고 복잡한 구조로, 주 경로에서 dense block을 사용하는데, 이로 인해 네트워크 용량은 커집니다.
이것들 외에
Residual scaling: 불안정성을 방지하기 위해 주 경로에 추가하기 전에 0과 1 사이의 상수를 곱해 residuals 스케일을 축소한다.
Smaller initialization: residual 구조는 초기 매개변수 분산이 작을 수록 더욱 쉽게 학습시킬 수 있다.
등의 기술도 이용하였습니다.
\
잔여 연결(Residual Connection): 잔여 연결은 네트워크를 깊게 만들 때 발생하는 그래디언트 소실 문제를 해결하기 위한 기법입니다. 이는 네트워크의 레이어를 통과하는 동안 정보가 손실되는 것을 방지하고, 그래디언트가 원래 입력으로 바로 전달될 수 있도록 합니다. 이를 통해 더 깊은 네트워크를 학습시킬 수 있습니다.
관련 논문: https://arxiv.org/abs/1512.03385v1
밀집 연결(Dense Connection): 밀집 연결은 각 레이어가 이전 레이어의 출력을 입력으로 받는 구조입니다. 이는 네트워크의 각 레이어가 이전 레이어에서 추출된 특징을 재사용할 수 있도록 해줍니다. 따라서 입력과 출력 간의 직접적인 연결을 통해 그래디언트가 더 잘 전달되고, 정보가 더 잘 보존됩니다.
관련 논문: https://arxiv.org/pdf/1608.06993.pdf
# 논문은 더 복잡하지만 간단하게 구현
import torch
import torch.nn as nn
# Residual in Residual Dense Block (RRDB)
class RRDB(nn.Module):
def __init__(self, channels, growth_channels=32, num_dense_layers=3):
super(RRDB, self).__init__()
self.conv_blocks = nn.ModuleList()
for _ in range(num_dense_layers):
self.conv_blocks.append(self.make_dense_block(channels, growth_channels))
self.conv1x1 = nn.Conv2d(channels + growth_channels * num_dense_layers, channels, kernel_size=1, stride=1, padding=0)
def make_dense_block(self, in_channels, growth_channels):
layers = []
for _ in range(5): # Each RIU contains 5 convolutional layers
layers.append(nn.Conv2d(in_channels, growth_channels, kernel_size=3, stride=1, padding=1))
layers.append(nn.ReLU(inplace=True))
in_channels += growth_channels
return nn.Sequential(*layers)
def forward(self, x):
dense_features = []
for conv_block in self.conv_blocks:
out = conv_block(x)
dense_features.append(out)
x = torch.cat([x, out], 1)
out = self.conv1x1(torch.cat(dense_features, 1))
out += x # Residual connection
return out
# Example usage:
input_channels = 64
rrdb_block = RRDB(input_channels)
input_data = torch.randn(1, input_channels, 64, 64) # Example input data
output = rrdb_block(input_data)
print(output.shape) # Printing the output shape
RRDB는 이러한 두 가지 개념을 결합하여 구성됩니다. 각 RRDB 블록은 여러 개의 Residual in Residual Units(RIU)로 구성되며, 각 RIU는 여러 개의 밀집 연결(Dense Connection)을 포함합니다. RIU 내에서 잔여 연결(Residual Connection)이 이루어지며, 블록 전체에서는 잔여 연결을 통해 그래디언트가 전달됩니다.
2) 2가지의 loss
- Relativistic GAN의 아이디어로 판별자가 절대값 대신 상대값을 예측
기존의 SRGAN의 판별자는 하나의 input 이미지(x)가 진짜이고 자연스러운 것일 확률을 추정했습니다.
relativistic discriminator는 실제 이미지(Xr)가 가짜 이미지(Xf) 보다 상대적으로 더 현실적일 확률을 예측합니다.

기존의 GAN에 비해 더 안정적이고 일관된 학습을 제공하는 GAN이며, RaGAN은 기본적인 구조를 유지하면서도 판별자(Discriminator)와 생성자(Generator) 간의 경쟁을 더 직관적으로 조절하는 방법을 도입했습니다.
RaGAN의 주요 아이디어는 "상대적인 진위(Realness)"에 중점을 두고 판별자의 학습을 개선하는 데 있습니다. 기존의 GAN은 생성된 이미지와 실제 이미지 간의 진위를 구별하도록 학습되는데, RaGAN은 이러한 진위를 상대적으로 측정하여 개선합니다. 즉, 판별자는 진짜 이미지가 가질 것으로 예상되는 실제 이미지보다 생성된 이미지가 더 "진짜 같은지"를 평가합니다.
이를 구현하기 위해 판별자의 손실 함수에 새로운 개념을 도입합니다. 기존의 GAN은 진짜 이미지를 입력으로 받아 진위를 평가하는 반면, RaGAN은 진짜 이미지와 생성된 이미지를 모두 입력으로 받아 진위를 판단합니다. 이때 진짜 이미지를 기준으로 진위를 평가하며, 생성된 이미지의 진위는 진짜 이미지에 대한 진위보다 높은지 낮은지를 판별합니다.
아래 코드는 RaGAN의 핵심 개념을 보여주기 위한 간단한 예시입니다.
import torch
import torch.nn as nn
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# Generator implementation
def forward(self, x):
# Generator forward pass
pass
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# Discriminator implementation
def forward(self, real_images, fake_images):
# Calculating relativistic loss
real_pred = self.forward_single(real_images) # Predictions for real images
fake_pred = self.forward_single(fake_images) # Predictions for fake images
return real_pred - fake_pred
def forward_single(self, x):
# Discriminator forward pass for a single set of images
pass
# Example usage:
# Instantiate Generator and Discriminator
generator = Generator()
discriminator = Discriminator()
# Example forward pass
real_images = torch.randn(64, 3, 64, 64) # Real images
fake_images = generator(torch.randn(64, 100)) # Generated fake images
# Calculate RaGAN loss
relativistic_loss = discriminator(real_images, fake_images)
- 활성화 부분전에 feature들을 사용해 perceptural loss를 개선하여 밝기의 일관성, 질감 복원에 강력한 supervision을 제공
기존에는 activation 이후에 feature map을 사용했지만, activation 전에 feature map을 사용함으로써 SRGAN보다 더 효과적인 perceptual loss(Lpercep)를 개발하였고, 이를 통해 기존에 있던 2가지의 문제점을 해결하였습니다.
- 매우 깊은 네트워크 activation 이후에 활성화된 features들은 매우 sparse함으로, 낮은 성능으로 이어진다.
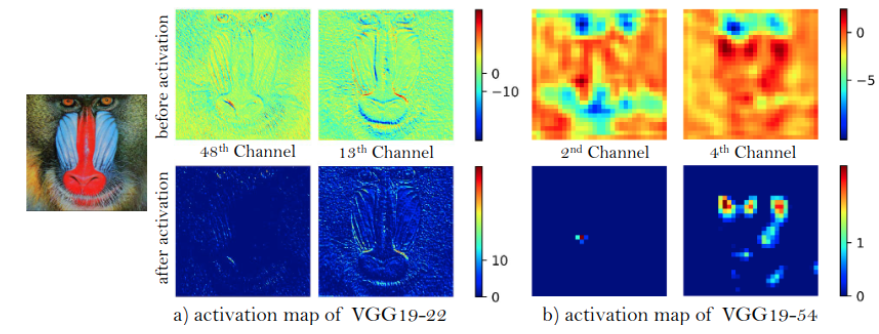
2. 활성화 후 feature들을 사용하는 것은 ground-truth 이미지와 비교했을 때 일관성이 없는 복원된 밝기를 유발한다.
(왼쪽 그래프 빨간색 gt, 파란색 after activation, 초록색 before activation)
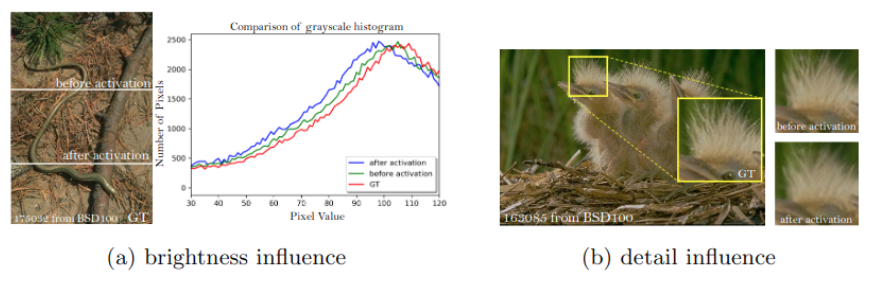
활성화 후 대부분의 feature들은 소극적(inactive)으로 된 반면, 활성화 전 feature들은 더 많은 정보들을 가지고 있습니다.
Perceptual loss는 사전 훈련된 신경망을 사용하여 이미지의 고수준 특징을 기반으로 생성된 이미지와 실제 이미지 간의 차이를 평가하는 손실 함수입니다. 이는 픽셀 단위 손실보다 더 자연스러운 이미지 생성과 복원에 도움을 줍니다.
주로 VGG 등의 신경망을 사용하여 이미지 특징을 추출하고, 이를 통해 perceptual loss를 정의합니다.
아래는 PyTorch를 사용하여 간단한 perceptual loss를 적용하는 예시 코드입니다.
import torch
import torch.nn as nn
import torchvision.models as models
# VGG 신경망을 가져와서 특정 레이어까지 잘라내는 함수
class VGGFeatures(nn.Module):
def __init__(self, layer_num):
super(VGGFeatures, self).__init__()
vgg = models.vgg19(pretrained=True)
self.features = nn.Sequential(*list(vgg.features.children())[:layer_num]).eval()
for param in self.features.parameters():
param.requires_grad = False
def forward(self, x):
return self.features(x)
# Perceptual loss 계산을 위한 함수
def perceptual_loss(fake_img, target_img, layer_num):
vgg = VGGFeatures(layer_num).to(device)
fake_features = vgg(fake_img)
target_features = vgg(target_img)
criterion = nn.MSELoss()
loss = criterion(fake_features, target_features)
return loss
# 예시: 가짜 이미지와 실제 이미지를 준비
fake_img = torch.randn(1, 3, 256, 256) # 가짜 이미지
real_img = torch.randn(1, 3, 256, 256) # 실제 이미지
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
fake_img = fake_img.to(device)
real_img = real_img.to(device)
# Perceptual loss 계산
layer_number_to_use = 5 # 원하는 VGG 레이어 선택
loss = perceptual_loss(fake_img, real_img, layer_number_to_use)
print(loss)
Total Loss
최종적으로 loss는 perceptual loss, RaGan loss, L1 loss가 사용됩니다.
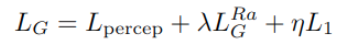
Network Interpolation
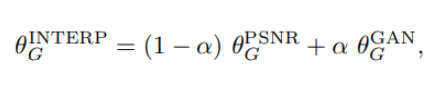
PSNR-oriented network(Gpsnr)을 학습한 후, 미세 조정을 통해 GAN-based network(Ggan)를 얻었습니다.
이것으로 기존 GAN 방식의 학습이 진행되면서 perceptual quality가 좋아져도 artifact가 생기는 문제를 어느정도 해결했으며 다시 모델을 재학습시킬 필요없이 지속적으로 지각 품질과 정확도의 균형을 유지할 수 있게 해줍니다.

즉, ESRGAN은 PSNR-oriented network인 Gpsnr을 학습한 후, 이를 기반으로 GAN-based network인 Ggan을 미세 조정하여 얻는 방식을 사용합니다.
ESRGAN 데이터셋 구성
정확한 LR-HR 이미지 쌍의 매칭이 중요하며 데이터셋은 고품질이여야 합니다.
- 고해상도 이미지 데이터셋: ESRGAN을 학습시키기 위해서는 고해상도(High-Resolution, HR) 이미지 데이터셋이 필요합니다. 이 데이터셋은 원본 고해상도 이미지로 구성되어야 하며, 이미지 해상도는 사용하려는 문제에 따라 결정됩니다. 예를 들어, 2배 또는 4배의 해상도 증가를 목표로 할 수 있습니다.
- 저해상도 이미지 데이터셋: 고해상도 이미지와 대응되는 저해상도(Low-Resolution, LR) 이미지도 필요합니다. 이 저해상도 이미지는 고해상도 이미지를 다운샘플링하여 생성됩니다. 일반적으로 Bicubic 또는 Lanczos와 같은 보간 알고리즘을 사용하여 고해상도 이미지를 저해상도로 줄입니다.
- 데이터 전처리: 이미지 데이터셋을 사용하기 전에 적절한 전처리가 필요합니다. 이는 이미지 크기 조정, 정규화, 노이즈 제거 등을 포함할 수 있습니다. 또한, HR 이미지와 LR 이미지 사이의 정확한 대응 관계를 유지하는 것이 중요합니다.
'딥러닝&머신러닝 > Paper Review' 카테고리의 다른 글
| To learn image super-resolution, use a GAN to learn how to do image degradation first (HLLHGAN) (1) | 2024.01.15 |
|---|---|
| Fast Nearest Convolution for Real-Time Effictient Image Super-Resolution[논문리뷰] (1) | 2024.01.10 |
| [논문 읽기]EfficientNet, Rethinking Model Scaling for Convolutional Neural Networks (0) | 2023.04.05 |
| CNN의 parameter 개수와 tensor 사이즈 계산하기 (0) | 2023.03.30 |
| NFNet 논문 번역(추후에 리뷰) (2) | 2023.03.28 |




댓글