(저해상도를 학습해서 화질개선 Gan을 학습하세요.)
Keywords: Image and face super-resolution, Generative Adversarial Networks, GANs.
[Abstract]
super-resulution 연구의 핵심은 낮은 해상도의 이미지를 높은 해상도로 증가시키는 방법에 중점을 두고 개발되었고
학습에 필요한 데이터는 주로 인위적으로 흐리게하거나 간단하게 이차 다운샘플링에 의해 생성되었습니다.
그러나, 이 논문은 기존의 방법이 좋은 결과를 만들어내지 못함을 주장합니다.
즉, 고화질데이터셋을 통해 인위적으로 만들어진 저화질데이터셋으로 학습한 모델에 실제 이미지를 적용하면 성능이 떨어진다는 것입니다.
이 문제를 우회하기 위해 two-stage process를 제안했습니다.
1) 고화질 이미지를 저화질 이미지(degrade, downsample)로 만드는 GAN을 학습합니다. 이를 위해 쌍이 없는 고화질과 저화질 이미지가 필요합니다.
2) 위의 모델을 가지고 생성된 이미지를 통해 Low-to-High GAN을 훈련하는 데 사용됩니다.
[Introduction]
이 논문은 화질 개선의 향상, 저화질 데이터의 품질(noisy, blurry 등) 그리고 인위적으로 만든 이미지로 인한 성능 저하에 대한 내용입니다.
(데이터 증강에 대한 문제는 인식, 객체 탐지에 이르기까지 다양한 TASK에서 도전하고 있는 문제입니다.)
우리가 메인으로 고민하는 것은 화질개선 시 '현실의 실제 저화질 이미지'에 대한 문제입니다.
(우리는 얼굴데이터를 사용하지만 잠재적으로 다른 카테고리에도 응용될 수 있습니다.)
기존의 화질개선 모델에 대한 논문의 대부분은 학습데이터로 인위적으로 만들어진 이미지(단순 저하, 흐림, 노이지 등)를 사용합니다.
그런데, 현실 세계의 환경(실제 low image에 관한)에 대한 관심은 데이터 생성 시 반영되지 못했습니다.
Main idea.
현실 세계의 화질개선을 위해서는 저하요인(blur(e.g. motion or defocus), compression artefacts, colour and sensor noise)에 대한 많은 고려사항이 있습니다.
위의 저하요인들은 보통 알려지지 않은 경우가 있고 효과적으로 학습하지 못하는 이유가 됩니다. 즉, 실제 이미지를 대상으로 학습하지 않고 인위적으로 학습한 모델을 가지고 현실 이미지를 TEST한다면 필연적으로 성능이 좋지 않을 것입니다.
현실의 저하요인을 반영하기 위해 논문에서는 GAN을 통해 고화질 이미지를 저화질로 만드는 학습과 사용을 제안하며, 모델을 통해 이미지를 저하하는 프로세스를 시도합니다.
특히, 제안 된 network는 학습 시 unpaired image data를 사용합니다. 단, 현실의 low image data와 서로 연관없는 high-resolution에 학습에 사용될 high image가 필요합니다.
이 기법이 달성된다면 현실적인 이미지 저하와 다운샘플링 그리고 화질개선 학습 시 high-resolution image의 짝으로 사용될 수 있습니다.
핵심은 Image degradation(HR to SR)을 GAN을 통해 학습시키자는 것이 메인 아이디어입니다.

[Method]
3.1 Overall architecture
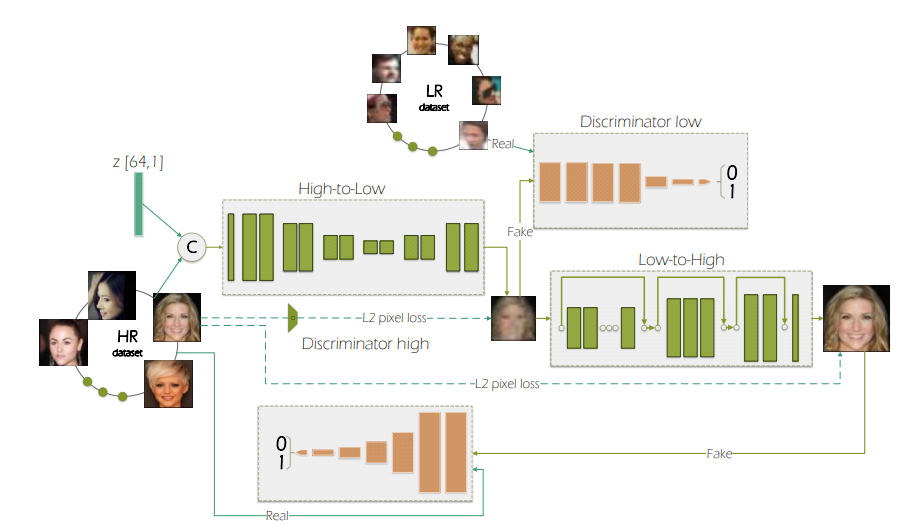
이 모델을 16*16의 저화질 이미지를 64*64 크기의 이미지로 화질개선합니다. 보통의 모델과 같이 Low-to-High 네트워크는 페어링된 LR 및 HR 얼굴 이미지로 훈련됩니다.
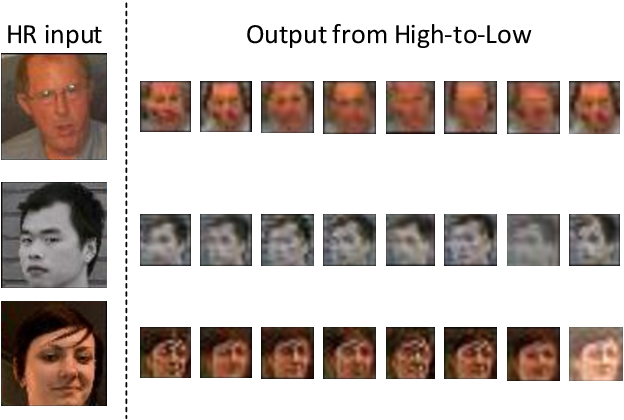
그런데 이 논문이 가지는 첫 번째 기본적인 차이점은 LR 이미지 생성 방법에 있습니다.
대부분의 이전 연구에서는 LR 이미지를 인위적으로 생성하여 실제의 저화질의 요소를 반영하지 못했습니다.
이를 완화하기 위해 본 논문에서는 또 다른 네트워크인 High-to-Low를 제안합니다.
특히 High-to-Low는 2개의 완전히 다른 데이터셋에서 비페어 데이터를 사용하여 훈련됩니다.
첫 번째 데이터셋에는 HR 이미지가 포함되어 있습니다.
두 번째 데이터셋에는 Widerface에서 얻은 흐린 및 저 품질 LR 이미지가 포함되어 있습니다.
이 논문과 이전 연구 간의 두 번째 기본적인 차이:
이 논문과 이전 연구 간의 두 번째 중요한 차이점은 양 네트워크를 훈련하는 데 사용되는 손실의 결합 방식에 있습니다.
우리 논문은 특히 GAN이 L2 픽셀 손실보다 더 강조되는 방향으로, 두 네트워크 간의 손실을 결합합니다.
기존 방법들은 픽셀 손실과 GAN 손실의 조합을 사용하지만 (경우에 따라 피처 손실도), GAN은 단순히 이미지를 더 선명하게 만드는 역할을 합니다.
그에 반해, 우리의 제안된 방법은 완전히 GAN 주도적이며, 픽셀 손실은 수렴 속도를 가속화하는 데에만 기여하며 특히 훈련 초기에는 GAN이 정체되지 않고 정체되지 않도록 도와주며 신원과 전반적인 얼굴 특성 (예: 자세, 표정)을 보존하는 역할을 합니다.
결국 모델의 핵심적인 내용은
HR->LR을 학습하는 High-to-Low Generator + Discriminator Low
LR->HR을 학습하는 Low-to-High Generator + Discriminator High
2개 GAN을 합쳐 End-to-End 방식으로 학습합니다.
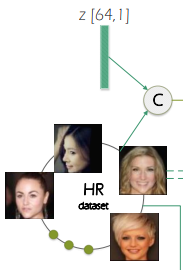
HR->LR을 학습할 때 이용되는 Noise인 z[64,1],
이건 HR Dataset에 Concatenate 해서 High-to-Low Generator의 input으로 사용합니다.
Noise에 따라 하나의 HR로 다양한 LR을 생성할 수 있습니다. Conditional GAN[34]과 유사한 방식이죠.
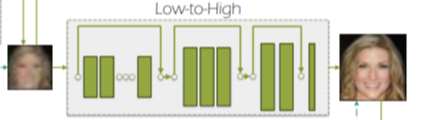
Test time에는 오로지 Low-to-High Generator만 이용해서 LR->HR의 super resolution을 진행합니다.
'딥러닝&머신러닝 > Paper Review' 카테고리의 다른 글
| [논문리뷰] Activating More Pixels in Image Super-Resolution Transformer(HAT) (0) | 2024.03.19 |
|---|---|
| Towards_Real-Time_4K_Image_Super-Resolution_CVPRW_2023 (0) | 2024.02.07 |
| Fast Nearest Convolution for Real-Time Effictient Image Super-Resolution[논문리뷰] (1) | 2024.01.10 |
| [논문리뷰] ESRGAN (1) | 2024.01.03 |
| [논문 읽기]EfficientNet, Rethinking Model Scaling for Convolutional Neural Networks (0) | 2023.04.05 |




댓글