Fast Nearest Convolution for Real-Time Effictient Image Super-Resolution
(실시간 효율적 이미지 초고해상도를 위한 빠른 최근접 합성곱 기술)
Keywords: Image super-resolution, real-time network, mobile device, nearest convolution, quantization
[Abstract]
딥러닝 기반의 SISR(Single Image Super Resolution)은 많은 각광을 받았고 GPU를 사용하면서 놀랄만한 성취를 이뤘다.
그러나, 최신의 SOTA Model은 많은 파라미터 수, 메모리, 계산 자원을 요구하기 때문에(즉 무겁다. 그래서 느리다.), 보통 모바일 CPU/NPU 환경에서는 저하된 inference 속도성능을 보여준다.
이 논문에서는, 간단한 일반 convolution network를 활용한 NCNet의 모듈을 제안한다. NCNet은 NPU에 친화적이며, Real Time SR TASK에서 믿을만한 성능을 보인다. nearest convolution은 기존의 SR Model보다 더 빠르며, 비슷한 성능을 보여줍니다. 그리고 Android NNAPI와 더 적합합니다.
*Android Neural Networks API (NNAPI)는 안드로이드 운영 체제에서 딥 러닝 및 머신 러닝 모델을 실행하기 위한 고성능 하드웨어 가속 인터페이스이다. NNAPI는 안드로이드 8.1 (Oreo) 이상의 버전에서 사용가능.
NCNet은 8비트 양자화를 통해 모바일 장치에 쉽게 배포할 수 있으며, 모든 주요 모바일 AI 가속기와 완벽하게 호환됩니다.
[Introduction]
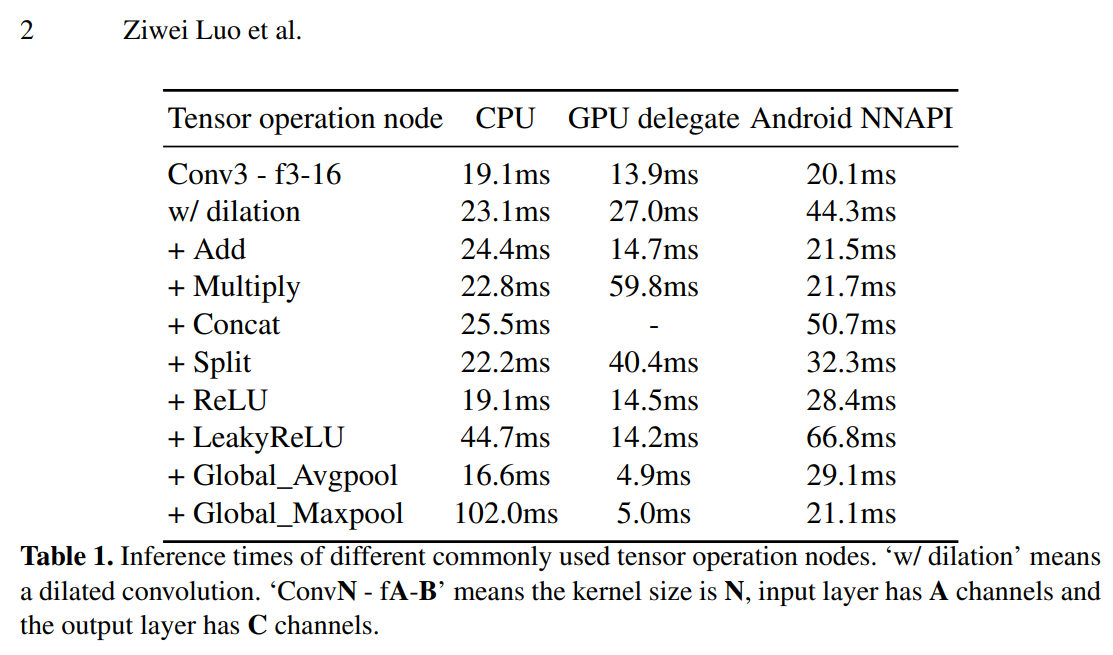

Image super-resolution (SR) is a fundamental task in computer vision that aims to reconstruct high-resolution (HR) images from their degraded low-resolution (LR) counterparts. It is a hot topic in recent years since its importance and ill-posed nature. The inherent challenge in the SR problem is that there always exists infinite solutions for recovering the HR image, and different HR images can be degraded to the same LR image, which makes it difficult to directly learn the super-resolution process.
SR(Super Resolution)은 Computer Vision의 근복적인 직무이며, 저화질(LR)을 고화질(HR)로 재구성하는 목표를 가지고 있습니다.
최근 몇 년간 이는 중요성과 ill-posed nature으로 화두가 되어왔습니다. SR 문제의 본질적인 난제는 HR 이미지를 복원하는 데 무한한 해결책이 항상 존재하며, 서로 다른 HR 이미지가 동일한 LR 이미지로 손상될 수 있다는 것입니다. 이로 인해 초해상도 과정을 직접 학습하는 것이 어려워집니다.
잘못된 조건의 성격(Ill-posed nature):
초해상도 문제는 해결하기 어려운 조건으로, LR 이미지에서 HR 이미지로의 변환은 여러 해가 될 수 있습니다. 즉, 한 개의 LR 이미지에서 원래의 HR 이미지를 정확하게 복원하는 것은 어렵습니다. 무한한 해결책의 존재: HR 이미지를 복원하기 위한 LR 이미지에서의 정보 손실로 인해 동일한 LR 이미지로부터 다양한 HR 이미지를 복원할 수 있습니다. 이는 복원 과정에서 발생할 수 있는 해결책의 다양성을 의미합니다. 직접적인 학습의 어려움: 이러한 무한한 가능성과 정보 손실로 인해, 초해상도 프로세스를 직접 학습하기 어렵습니다. LR 이미지에서 HR 이미지로의 직접적인 매핑을 학습하는 것이 어려워집니다. 종합하자면, 초해상도 문제는 정보의 손실과 해결책의 다양성으로 인해 복원 과정이 어렵고, 이러한 특성들로 인해 초해상도 작업을 직접적으로 학습하는 것이 어려움을 겪고 있습니다.
During the past decade, we have witnessed the remarkable success of deep neural network (DNN) based techniques in computer vision [23,14,13,32]. SR algorithms that are based on deep convolution networks have attracted lots of attention and rapidly developed. As a result, many works have achieved impressive results on kinds of SR tasks [37, 6, 4,5]. However, most superior methods heavily rely on using large networkcapacities and model complex to improve the SR performance, which limits their practicability on real-world resource-constrained mobile devices.
지난 10년 동안 Computer vision 분야에서 Deep neural network(DNN)의 놀랄만한 성과를 목격했습니다. DNN을 기반으로한 SR algorithmes도 관심을 끌었고, 급속히 개발되었고 결과적으로 많은 SR TASK의 연구는 인상적인 성과를 얻을 수 있었습니다.
그러나, 우수한 MODEL들은 SR의 성능을 위해 모델의 큰 용량과 복잡성에 의존하여 실제 자원이 제한된 모바일 장치에서 실용성이 제한됩니다.
In order to apply DNN-based SR models to smartphones, a new research line called efficient super-resolution is developed where various methods have been proposed to reduce the model complexity and inference time [39,25].
DNN을 기반으로한 SR모델을 스마트폰에서 지원하기 위해서, 모델 복잡성과 추론 시간을 줄이기 위한 다양한 방법들이 제안된 '효율적 초해상도(efficient super-resolution)'라는 새로운 연구 분야가 개발되었습니다.
In order to apply DNN-based SR models to smartphones, a new research line called efficient super-resolution is developed where various methods have been proposed to reduce the model complexity and inference time [39,25].
DNN을 기반으로한 SR모델을 스마트폰에서 지원하기 위해서, 모델 복잡성과 추론 시간을 줄이기 위한 다양한 방법들이 제안된 '효율적 초해상도(efficient super-resolution)'라는 새로운 연구 분야가 개발되었습니다.
A representative work is the IMDN [15], which proposes an information multi-distillation block that uses feature distillation and selective fusion parts to compress the model‘s parameters while preserving SR performance.
IMDN [15]는 모델의 매개변수를 압축하면서 SR(고해상도) 성능을 유지하는 데 특징 압축 및 선택적 융합 부분을 활용하는 정보 다중 증류 블록을 제안하는 대표적인 작품입니다.
IMDN의 개념을 간소화한 코드
import torch
import torch.nn as nn
# IMDN 모델 정의
class IMDN(nn.Module):
def __init__(self, num_channels, num_blocks):
super(IMDN, self).__init__()
# 특징 압축을 위한 레이어 정의
self.feature_distillation = nn.Sequential(
nn.Conv2d(num_channels, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
# 추가적인 Conv 레이어들과 활성화 함수들을 적용하여 특징 압축 수행
)
# 선택적 융합을 위한 레이어 정의
self.selective_fusion = nn.Sequential(
nn.Conv2d(num_channels, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
# 추가적인 Conv 레이어들과 활성화 함수들을 적용하여 선택적 융합 수행
)
# Residual Dense Blocks (RDBs) 정의
rdb_layers = []
for _ in range(num_blocks):
rdb_layers.append(ResidualDenseBlock(64)) # RDB 블록 추가
self.rdb_blocks = nn.Sequential(*rdb_layers)
# 최종 출력 레이어 정의
self.output_conv = nn.Conv2d(64, num_channels, kernel_size=3, stride=1, padding=1)
def forward(self, x):
# 입력 이미지 x에 대해 특징 압축과 선택적 융합 수행
features = self.feature_distillation(x)
fusion = self.selective_fusion(x)
# 특징과 융합된 특징을 결합
combined_features = features + fusion
# Residual Dense Blocks (RDBs) 적용
out = self.rdb_blocks(combined_features)
# 최종 출력 레이어를 통해 고해상도 이미지 생성
output = self.output_conv(out)
# 최종 출력 반환
return output
# Residual Dense Block (RDB) 정의
class ResidualDenseBlock(nn.Module):
def __init__(self, num_channels):
super(ResidualDenseBlock, self).__init__()
# 여러 개의 Conv 레이어와 활성화 함수로 구성된 RDB 내부 구조
self.conv1 = nn.Conv2d(num_channels, num_channels, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(num_channels * 2, num_channels, kernel_size=3, stride=1, padding=1)
self.conv3 = nn.Conv2d(num_channels * 3, num_channels, kernel_size=3, stride=1, padding=1)
self.conv4 = nn.Conv2d(num_channels * 4, num_channels, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
# 입력을 첫 번째 Conv 레이어에 통과시킴
out1 = self.relu(self.conv1(x))
# 두 번째 Conv 레이어에 이전 단계의 출력과 함께 통과시킴
out2 = self.relu(self.conv2(torch.cat((x, out1), 1)))
# 이런 식으로 RDB 내부의 Conv 레이어들을 통과시킴
out3 = self.relu(self.conv3(torch.cat((x, out1, out2), 1)))
out4 = self.relu(self.conv4(torch.cat((x, out1, out2, out3), 1)))
# RDB의 최종 출력 반환
return out4
# 모델 인스턴스 생성 (예시: 입력 채널 수는 3, RDB 블록 수는 5로 설정)
num_channels = 3 # 입력 이미지 채널 수
num_blocks = 5 # RDB 블록 수
imdn_model = IMDN(num_channels, num_blocks)
# 모델 사용 예시 (임의의 입력 이미지)
input_image = torch.randn(1, num_channels, 64, 64) # 입력 이미지 예시 (batch_size, channels, height, width)
output_image = imdn_model(input_image) # IMDN 모델을 사용하여 SR 수행
Later, RFDN [27] builds a residual feature distillation network on top of IMDN but replaces all channel splitting operations with 1×1 convolutions and adds feature distillation connections.
후에, RFDN [27]은 IMDN 위에 잔여 특징 증류 네트워크(residual feature distillation network)를 구축하지만 모든 채널 분할 작업을 1×1 컨볼루션으로 대체하고 특징 증류 연결을 추가합니다.
By doing so, RFDN has won 1st place in the AIM 2020 efficient super-resolution challenge [39]. In addition, some simplified attention mechanisms are also used in the efficient super-resolution task [43,28].
그렇게함으로써, RFDN은 1등도 하고 super-resolution task에서 보편적으로 사용하는 메커니즘이 되었다.
Compared with traditional superior SR networks, all these efficient-designed methods perform well and fast on desktop GPU devices. But we noticed that performing super-resolution on smartphones has much tighter limits on computing capacities and resources: a restricted amount of RAM, and inefficient support for many common deep learning layers and operators.
기존의 우수한 SR Networks와 비교하면 그들이 효율적으로 설계한 methods는 데스크탑의 GPU 환경에서 좋은 성능과 속도를 보여줬습니다.
그러나, 우리는 위 super-resolution 모델이 스마트폰 환경에서 너무나 한정적인 연산 용량과 제한적인 RAM 자원으로 인해 동일한 성능이 나올 수 없음을 알고 있으며, 스마트폰이 일반적인 딥러닝 레이어와 연산에 대한 비효율적인 지원을 합니다.
A mobile-friendly SR model should take care of the compatibility of tensor operators on mobile NPUs. We need to know what operations are particularly optimized by the mobile NN platform (Synaptics Dolphin platform).
모바일 친화적인 초해상도(SR) 모델은 모바일 NPUs(Neural Processing Units)에서의 텐서 연산자의 호환성을 고려해야 합니다. 모바일 NN 플랫폼(Synaptics Dolphin 플랫폼)에서 특히 최적화된 어떤 연산이 있는지 알아야 합니다.
Recent works [9,3,17] have investigated some limiting factors of running deep networks on a mobile device and what kind of architecture can be friendly to INT8 quantization. They propose several useful techniques such as “anchor-based residual learning”, “Clipped ReLU”, and “QuantizeAware Training” to accelerate inference while preserving accuracy on smartphones. However, there is still no basic experiment that can illustrate the difference of tensor operators on different smartphone AI accelerators.
최근 연구들 [9, 3, 17]은 모바일 기기에서 딥 네트워크를 실행하는데 제한 요인과 INT8 양자화에 친화적인 어떤 종류의 아키텍처가 가능한지를 조사했습니다.
그들은 "앵커 기반 잔차 학습(Anchor-based Residual Learning)", "Clipped ReLU", 그리고 "양자화 인식 훈련(QuantizeAware Training)"과 같은 몇 가지 유용한 기술을 제안하여 스마트폰에서 정확도를 유지하면서 추론을 가속화하는 방법을 제시했습니다.
하지만, 여전히 서로 다른 스마트폰 AI 가속기에서 텐서 연산자의 차이를 설명할 수 있는 기본 실험이 없습니다.
In this paper, we provide a comprehensive comparison of inference times for kinds of tensor operation nodes and network architectures, as shown in Table 1 and Table 2. We use DIV2K 3× [37] as the training and evaluation dataset. All experiments are evaluated on AI Benchmark application [16,19]. As one can see, some commonly used deep learning techniques (e.g., dilated convolution, concatenation, channel splitting, and LeakyReLU) are not compatible with mobile Android NNAPI, even though they have a good performance on CPU and GPU delegate. Based on these experiments and analysis, we design a plain network that only contains 3×3 convolution layers and ReLU activation functions. Moreover, we propose to use a novel nearest convolution to replace the traditional nearest upsampling in network residual learning, which further speeds up the inference and achieves the same effect as nearest interpolation residual learning.
논문에서는 다양한 텐서 연산 노드 및 네트워크 아키텍처의 추론 시간을 종합적으로 비교하였습니다.
실험 결과, 몇 가지 딥 러닝 기술이 모바일 Android NNAPI와 호환되지 않음을 확인했습니다.
이에 따라 단순한 네트워크 아키텍처와 새로운 최근접 컨볼루션을 제안하여 추론 속도를 높이고 최근접 보간 잔차 학습과 동일한 효과를 달성하였습니다.
새로운 최근접 컨볼루션을 제안합니다. 이로써 추론을 더 빠르게 수행하며, 최근접 보간 잔차 학습과 동일한 효과를 달성합니다.
– We provide a comprehensive comparison of inference times for different tensor operators and network architectures on a smartphone, which tells us what operation is good for mobile devices and should be incorporated into the network.
– We propose a fast nearest convolution plain network (NCNet) that is mobile-friendly and can achieve the same performance as nearest interpolation residual learning while saving approximately 40ms on a Google Pixel 4 smartphone.
주요 내용 요약:
-스마트폰에서 다양한 텐서 연산자와 네트워크 아키텍처의 추론 시간을 종합적으로 비교하여 어떤 연산이 모바일 장치에 적합하며 네트워크에 통합되어야 하는지를 알려주는 포괄적인 비교를 제공합니다.
-Google Pixel 4 스마트폰에서 약 40ms를 절약하면서도 모바일 친화적인 빠른 최근접 컨볼루션 평면 네트워크 (NCNet)를 제안하였습니다. 이 네트워크는 최근접 보간 잔차 학습과 동등한 성능을 달성할 수 있습니다.
[Related Work]
2.1 Single Image Super-Resolution
단일 이미지 초고해상도(SISR)는 컴퓨터 비전 분야에서 중요하고 해결하기 어려운 문제로, 다양한 연구가 이루어져왔습니다. 초기에는 SRCNN [35]과 같이 간단한 합성곱 신경망을 이용해 HR 및 LR 이미지 쌍을 만들고 초고해상도 이미지를 생성하는 방법이 등장했습니다. 이후에 VDSR [35], ESPCN [34], EDSR [26] 등의 더 깊고 효율적인 네트워크가 등장했습니다. 최근엔 VGG 손실, 지각 손실, GAN 손실 등의 고급 손실 함수를 도입하여 시각적 품질을 향상시키는 노력도 있었습니다. 그러나 이러한 방법들은 일반적으로 많은 리소스를 요구하여 현대적인 모바일 장치에 적용하기 어려운 상황입니다.
2.2 Efficient Image Super-Resolution
스마트폰 애플리케이션에 모델을 적용하는 수요가 증가함에 따라 효율적인 이미지 초고해상도 기술에 대한 연구가 집중되고 있습니다. CARN [2]은 경량화된 SR 네트워크를 구현하기 위해 카스케이드 잔차 블록과 그룹 컨볼루션을 사용합니다. IMDN [15]은 정보 다중 증류 네트워크를 활용하여 계층적 특징을 추출하고 메모리 및 연산량을 줄입니다. RFDN [27]은 1×1 컨볼루션 레이어를 이용하여 채널 분할 연산을 대체하는 특징 증류 블록을 도입하여 네트워크를 개선합니다. 이러한 네트워크들은 데스크탑 CPU/GPU에서 효율적으로 초고해상도 작업을 수행할 수 있지만, 스마트폰과 같은 모바일 장치에서는 리소스가 제한적이어서 실제 애플리케이션에 적용하기 어렵습니다. ABPN [9]과 XLSR [3]은 Mobile 2021 Real-Time Single Image Super-resolution Challenge [17]에서 우승한 모바일용 가벼운 SR 네트워크를 제안했습니다.
[Method]
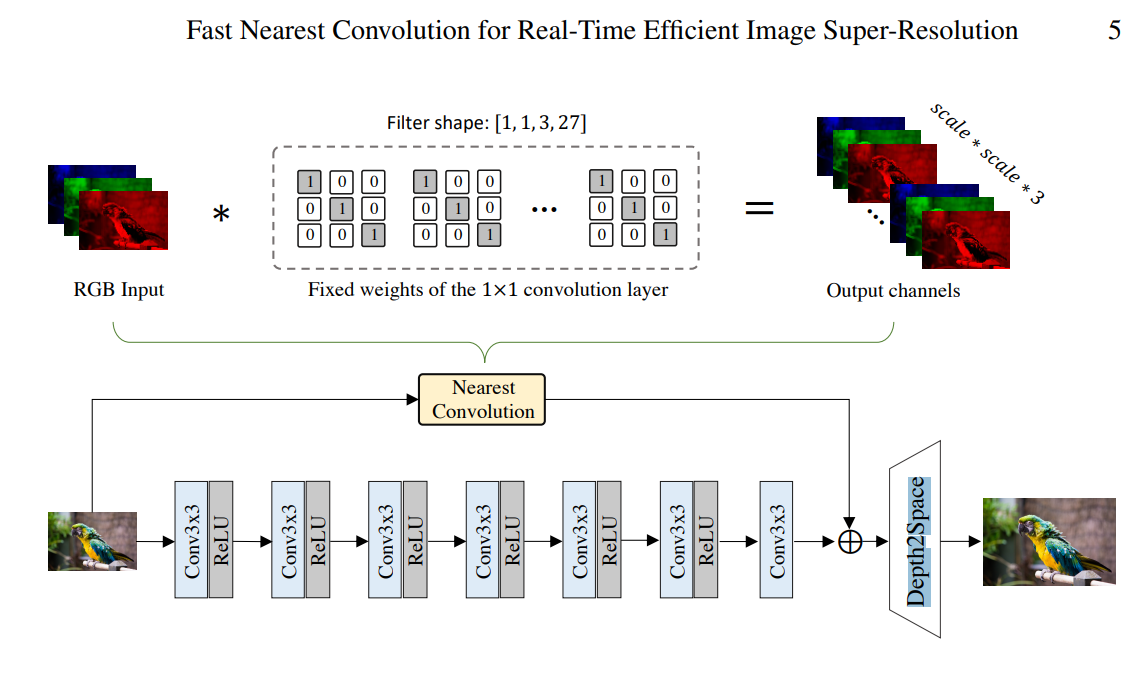
우리는 가장 가까운 컨볼루션 모듈의 주요 아이디어를 설명합니다. 수동으로 설계된 백본(backbone)과 가장 가까운 컨볼루션을 잔차 학습(residual learning) 형태로 결합함으로써, Figure 1에 나타난 것과 같이 최종적으로 효율적인 SR(초해상도) 네트워크를 얻을 수 있습니다.
- Figure 1
제안된 NCNet의 네트워크 구조입니다. 주요 네트워크 백본은 잔차를 학습하고, 가장 가까운 컨볼루션 모듈은 저주파 정보를 최종 결과물에 직접 전달합니다. 또한, 가장 가까운 컨볼루션은 가장 가까운 보간과 동일한 성능을 달성하지만 병렬로 실행될 수 있습니다.
- Network Architecture Selection
NPU의 병렬 속성을 활용하기 위한 모든 실험의 결과
1) 기준 작업 노드는 3x3 컨볼루션(convolution)으로 설정(5x5 컨볼루션은 낭비적, 1x1 컨볼루션은 성능을 얻기에 납득하기 어려움)
2) 최근에 많이 사용하고 있는 'LeakyReLU', 'Global Average Pooling' 제외(시간이 많이 소요) 하고 ReLU
3) 출력 채널은 16개로 설정
4) 모든 연산을 INT8로 양자화하여 진행
5) ABPN에서 영감을 받아 잔차 학습을 통해 최종 결과물 개선(Filter shape이 [1, 1, 3, 27] 적용)
- Nearest Convolution(Depth-to-Space)
Nearest Convolution 모듈은 1×1 스트라이드 1의 특수한 컨볼루션 레이어로, 가중치를 동결하여 Nearest 보간을 수행합니다. 입력 이미지를 반복하여 HR 이미지를 생성하며, 모바일 GPU/NPU에서 효율적으로 실행됩니다. 제안된 Nearest Convolution은 원래의 Nearest 보간보다 약 40ms 시간을 절약합니다.
import tensorflow as tf
# Nearest Convolution 모듈 구현 (TensorFlow 예시)
class NearestConvolution(tf.keras.layers.Layer):
def __init__(self, scale_factor):
super(NearestConvolution, self).__init__()
self.scale_factor = scale_factor
def build(self, input_shape):
kernel_shape = (1, 1, input_shape[-1], self.scale_factor ** 2 * 3)
self.kernel = self.add_weight("kernel", shape=kernel_shape, initializer='ones', trainable=False)
# nearest interpolation 설정
self.kernel.assign(tf.reshape(tf.eye(self.scale_factor), (1, 1, self.scale_factor, self.scale_factor, 1, 1)))
def call(self, inputs):
return tf.nn.conv2d(inputs, self.kernel, strides=[1, 1, 1, 1], padding='SAME')
print("___________________________구분선___________________________")
# 그냥 쉽게.../
depth_to_space = Lambda(lambda x: tf.nn.depth_to_space(x, scale_factor))
x = depth_to_space(x)
clip_func = Lambda(lambda x: tf.clip_by_value(x, 0., 255.))
x = clip_func(x)양자화에 관련된 예시 코드
import tensorflow as tf
# 모델 불러오기 예시 (사전 학습된 모델을 사용할 수도 있습니다)
model = tf.keras.applications.MobileNetV2(weights='imagenet', input_shape=(224, 224, 3))
# 모델 컴파일
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 모델 양자화 (가중치 양자화)
converter = tf.lite.TFLiteConverter.from_keras_model(model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
quantized_model = converter.convert()
# 양자화된 모델을 파일로 저장
with open('quantized_model.tflite', 'wb') as f:
f.write(quantized_model)'딥러닝&머신러닝 > Paper Review' 카테고리의 다른 글
| Towards_Real-Time_4K_Image_Super-Resolution_CVPRW_2023 (0) | 2024.02.07 |
|---|---|
| To learn image super-resolution, use a GAN to learn how to do image degradation first (HLLHGAN) (1) | 2024.01.15 |
| [논문리뷰] ESRGAN (1) | 2024.01.03 |
| [논문 읽기]EfficientNet, Rethinking Model Scaling for Convolutional Neural Networks (0) | 2023.04.05 |
| CNN의 parameter 개수와 tensor 사이즈 계산하기 (0) | 2023.03.30 |




댓글