논문 관련 링크: https://paperswithcode.com/paper/towards-real-time-4k-image-super-resolution
Papers with Code - Towards Real-Time 4K Image Super-Resolution
Implemented in 2 code libraries.
paperswithcode.com
논문을 읽은 이유:
현재 연구소에서 개발중인 군용 Super-Resolution Task 모델의 아키텍처 구성 요소를 바꾸는 과정에서 영감을 얻고자 했다. 특히, Real-Time이라는 키워드에 이끌려 논문을 열었다.
[Abstract]
현재는 FHD, UHD가 화질의 기준이 되어버렸습니다. 이로인해 많은 곳에서 기준을 맞추기 위해 '실시간'으로 화질개선을 시도했지만 GPU를 사용환경에서도 성능 목표를 맞추기가 어려운 과제였습니다. 이 논문에서는 이미지 720p 및 1080p 해상도에서 4k로 효율적으로 업스케일링 하는 것을 목표로 하는 초해상도 모델 설계 및 기술의 효율적인 면을 분석하여 제시했습니다.
모델의 아키텍처의 경우 Deep Feature Map을 축소하여 전체적인 연산량을 감소시키는 동시에 화질 개선의 성능을 유지하는데 초점을 두고 지금까지의 화질개선에 사용되었던 아키텍처를 기반으로 점진적으로 설계를 수정하여 high-frequency를 효율적으로 추출하도록 구성했습니다.
(점진적으로 아키텍처를 변경하는 과정에서 re-parameterization, NAFNet Block, pizel-unshuffling 등을 도입하거나 통합하거나 제외하면서 성능을 향상시켰습니다.)
[Introduction]
Super Resolution이란 저해상도 이미지를 고해상도 이미지로 복원하는 Task입니다. 이를 위해 고전적인 방법이 존재했고 지금은 딥러닝 기반의 방법론으로 빠르게 해결방법이 전환되었습니다. 그 과정에서 크고 깊은 네트워크를 통해 복원에 대한 좋은 성능을 달성했지만 동시에 많은 연산량과 긴 처리 시간을 요구했고 상용화나 실제 탑재(미디어, 콘텐츠, 송수신 방법 등등)를 위해서는 필수적으로 경량화나 효율적인 솔루션이 필요해졌습니다.
이 논문에서는 위의 문제를 해결하고자 빠르고 가벼운 모델의 아키텍처를 제시하여 연산 효율성(+runtime)을 높이는 동시에 다른 모델과 유사한 성능을 유지하는 것으로 달성 목표로 잡았습니다.
아키텍처의 핵심
Deep Features의 크기를 줄이면서 HF(high-frequency)의 정보를 유지시킨다.
이를 위해,
1) NAFNet Block을 통해 효율적인 계산을 하는 방법
2) 모델 설계 단순화 & re-parameterization 적용을 통한 런타임 줄임
3) HF(high-frequency) 추출 후 병렬 브랜치를 통해 정제
등을 통해 TEST
[Method]
Model Architecture
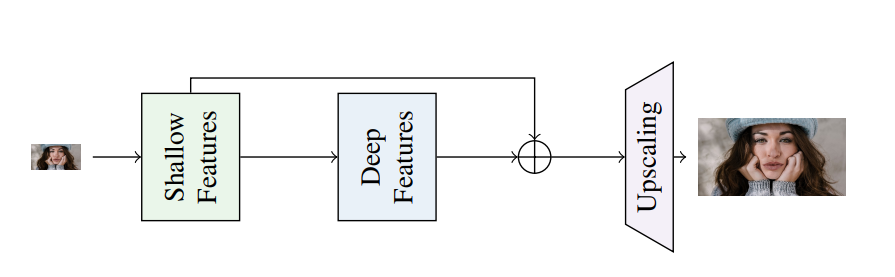
앞서 언급했던 것처럼 기본적인 구조와 얕고 가벼운 디자인을 중점에 두며 실시간 처리의 성능을 우선하여 개발했습니다.
3 × 3 컨볼루션 스택 + GeLU의 구성으로 아키텍처 연구를 시작하며, 점차적으로 구성을 변경하며 테스트를 진행했습니다.
LR 이미지에는 HF의 정보가 이미 부족하기 때문에 결과적으로 학습과정에서 SR 성능에 좋지 않은 영향을 준다는 것이 입증되었습니다. 그래서 학습 시에 다양한 크기의 LR 이미지를 입력으로 사용했고 HF 정보를 얻고 처리하는데 효과적인 결과를 얻었습니다.(코드 상에서는....모르겠음)
# Method-Enhancing High Frequencies
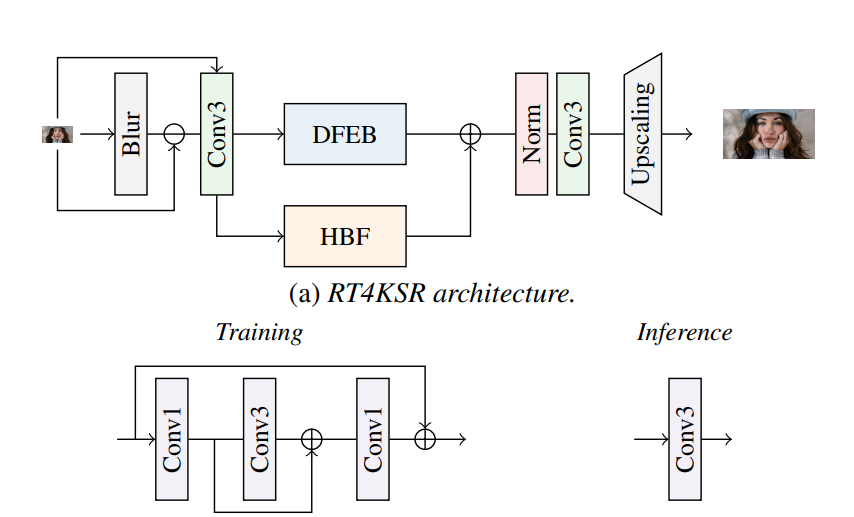
전체적인 구성도
image input -> 정보가 가장 많은 때 HF(High Frequency) 구성 요소 추출 -> 공유 컨볼루션 -> 고주파 전용 HFB(고주파 브랜치) + Deep Feature 전용 DFEB -> HF + Deep Feature Map
(i) average pooling을 통해 LR 입력의 크기를 줄이고 즉시 Nearest Neighbor 보간법을 사용하여 원래 해상도로 다시 업스케일링합니다.
(ii) blurred이미지를 얻기위해 input에 저렴한 Gaussian blur을 작업합니다.
self.gaussian = torchvision.transforms.GaussianBlur(kernel_size=5, sigma=1)
두 접근 방식 모두 신호의 균일성을 나타내는 이미지를 생성하며, 이를 초기 LR 입력에서 빼서 HF 구성 요소를 얻습니다.
위의 각 데이터 추출 기법은 서로 다른 영향을 줍니다.
# Method-Compressing Deep Features
이슈: Real Time을 위해서 모델을 최적화하고 경량화하는 과정에서 성능 저하가 발생함.
DFEB(Deep Feature Extraction Branch)에 Down-and-Up 방식을 적용할 때 pooling에 의한 재구성 정확도 손실이 나타났습니다.(흥미로운점: Deep Features를 축소할 때 HFB(High Frequency Branch)를 통합하면 크게 성능 향상을 가져오지 못함. )
위의 문제를 해결하기 위해서 PixelUnshuffle 연산을 사용하여 특성을 다운샘플링하는 방법을 탐구했습니다. PixelUnshuffle 연산을 통해 공간 차원이 s의 배수로 축소될 때, 채널 차원은 s^2의 배수로 증가했습니다. PixelUnshuffle을 그대로 적용하면 SR의 정확도는 향상되지만, 효율성은 감소합니다. 그래서 이를 조절(추론 효율성)하기 위해서 다시 채널을 압축하며 매핑할 수 있는 3 × 3을 배치했습니다. 즉, LR 입력이 셔플된 후 컨볼루션(3 × 3)을 통과하도록 구조를 재조정했습니다.
HF 및 LR 특성은 DFEB 및 HFB 모듈을 통해 추가로 학습이 진행되며, 업스케링 단계 전에 병합한 다음 출력 해상도를 ×4( ×2 SR의 경우)로 증가시킵니다.
- DFEB 및 HFB 모듈의 모델링 성능을 향상시키기 위한 내용
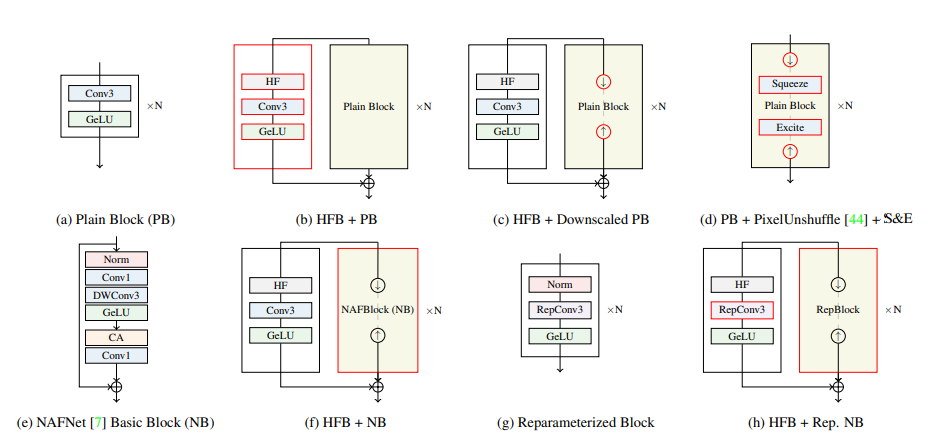
# Method-Increasing Block Complexity
기본적인 3 × 3 컨볼루션과 GeLU 활성화로 구성된 기존 아키텍처의 반복은 표현 능력이 제한적입니다. 그러나 최근에 NAFNet이 더 복잡한 블록 디자인을 통해 강력한 재구성 능력을 보여주었으며, 기존 블록의 성능을 향상시키기 위해 NAFNet 블록의 기술을 도입했습니다. 구체적으로는, 3 × 3 컨볼루션을 depthwise separable convolution으로 대체합니다. 이는 GeLU 비선형성을 거친 후에 C에서 2C로 특징 차원을 증가시키는 과정이며, Channel Attention, LayerNorm 및 skip-connection이 포함되어 있습니다. 성능 향상을 위해 Channel Attention은 표준 버전 대신 효율적인 버전으로 대체되었습니다. 최종적으로 1 × 1 컨볼루션을 사용하여 특징 차원을 다시 C로 매핑했습니다.
예상대로 모델의 성능은 향상되었지만, 런타임도 증가했습니다. 이 문제를 해결하기 위해 중간 레이어를 다운샘플링하는 것을 고려했지만, 다운샘플링은 모델이 달성한 정확도 향상을 유지하는 데 어려움이 있었습니다. 수정된 아키텍처는 이 연구 사례에는 적합하지 않았습니다.
# Method-reparameterization
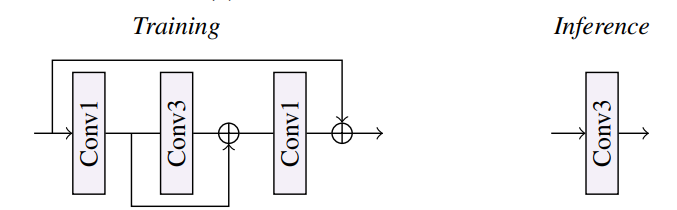
많은 팀들이 사용하고 성능을 향상시킨 reparameterization을 주의 깊게 조사한 결과, DFEB 내의 depthwise separable convolution을 reparameterizable residual block (RRB)으로 교체했습니다.
RRB는 1 × 1 컨볼루션을 사용하여 C 채널 차원을 '2배'로 확장시킵니다. 그 후 3 × 3 컨볼루션을 통해 높은 차원에서 학습된 특성을 더욱 강화합니다. 이는 모델이 추출한 특성을 더 추상화된 형태로 변환하고 풍부한 표현을 얻기 위한 과정으로, 마지막 1 × 1 컨볼루션 단계에서는 채널 수를 C로 줄이면서 가장 중요하거나 구별력 있는 특성만을 보존합니다.
추론 단계에서는 RRB(Rearward Recurrent Block)를 단일 3 × 3 컨볼루션으로 요약할 수 있습니다. 이로써 처리 시간을 줄이면서도 높은 특성 채널의 표현 능력을 유지할 수 있습니다. 게다가, 효율적인 Channel Attention 모듈, 최종 1 × 1 컨볼루션, 그리고 지역적인 잔여 연결을 제거하여 RRB 앞에 있는 정규화 연산만을 유지합니다. 또한, HFB(Higher Feature Block)의 모델 용량을 확장하기 위해 3 × 3 컨볼루션을 RRB로 대체함으로써 성능을 향상시켰습니다.
[Towards Learning the High Frequency Details]
고주파 세부정보(high frequencies)을 명시적으로 모델링하는 것이 모델의 핵심 개념입니다.
고주파 세부정보(ex. edges, contours)를 SR이미지, HR이미지에서 수집하기 위해서 Gaussian blur 연산을 사용합니다.
위의 내용을 통해 최적화 작업의 보조적인 역할을 하게 됩니다. 즉 고주파 맵 간의 L1거리를 최소화하는 작업을 통해 모델의 성델 성능을 향상시키는데 도움을 줍니다.
HF_Loss(고주파 손실함수) = [(HR Target Image - (HR Target Image * 가우시안 블러 연산)) - (SR(고해상도) 출력 이미지 - (SR(고해상도) 출력 이미지 * 가우시안 블러 연산))]L1 norm
*Edges(가장자리): 이미지에서 갑작스럽게 픽셀 값이 변하는 부분을 나타냅니다. 이는 주로 물체의 경계 또는 두 개의 서로 다른 영역 간의 경계에서 나타납니다.
*Contours(윤곽): 물체의 외부 경계를 나타냅니다. 이는 주로 물체와 배경 간의 경계를 따라 나타나며, 물체의 형태를 정의합니다.




댓글