논문: https://arxiv.org/pdf/2402.19387.pdf
github: https://github.com/lbc12345/SeD
[Abstract]
GANs은 super resolution task에서 널리 사용되었습니다. 관련 내용 중에서 'Discriminator' real-world의 고화질 이미지로 만드는 adversarial training에서 활용되어졌습니다.
그러나, 이미지의 텍스처 질감을 너무 과도하게 강조하여 실제와는 다른 가상적인 질감을 생성할 수 있으며 모델이 예상한 결과와 다르게 생성물을 만들어낼 수 있습니다. 이를 완화하기 위해서, 간단하고 효과적인 'SeD'를 제안했습니다. 이는 SR 네트워크가 이미지의 의미론적 정보를 조건으로 도입함으로써 세밀한 분포를 학습하도록 장려합니다. 구체적으로, 우리는 훈련된 잘된 의미 추출기에서 이미지의 의미론적 정보를 추출하는 것을 목표로 합니다.
다른 의미 하에서, 감별자는 개별적으로 실제-가짜 이미지를 구별하고 적응적으로 구별할 수 있으며, 이는 초해상도 네트워크가 더 세밀한 의미론적 질감을 학습하도록 이끕니다.
정확하고 풍부한 의미를 얻기 위해 최근 인기 있는 사전 훈련된 비전 모델(PVM)과 함께 최대한 활용하며 광범위한 데이터셋을 함께 합니다. 그리고 잘 설계된 공간 교차-주의 모듈을 통해 그의 의미론적 특징을 감별자에 통합합니다.
[Introduction]
딥러닝은 단일 이미지 초고해상도(SISR) 작업의 큰 발전을 가속화했습니다. SISR은 저해상도(LR) 입력에서 생생한 고해상도(HR) 이미지를 복원하는 작업입니다. 기존 SISR 방법에는 두 가지 주요 I know you are with me최적화 목표가 있습니다. 하나는 목적 함수 및 주관적 품질을 향상시키기 위한 것이며, 다른 하나는 픽셀 단위 손실 함수(예: L1 손실 및 MSE 손실)의 제약을 통해 SR 네트워크의 표현 능력을 향상시키기 위한 것입니다. 그러나 픽셀 단위 손실 함수는 SR 네트워크가 유망한 환각 능력을 갖도록 할 수 없으며 텍스처 생성에서 성능이 저하되고 만족스럽지 않은 주관적 품질을 낳습니다.
주관적 품질을 향상시키기 위해 왜곡된 이미지에 사람이 좋아하는 텍스처를 생성하는 것이 필요합니다. 생성적 적대 신경망(GAN) [18]에서 영감을 받아 일련의 선구적인 작업들은 SR 네트워크를 생성기로 간주하고 SR 네트워크에 현실적인 텍스처 생성 능력을 부여하기 위해 판별자를 도입했습니다. SR 네트워크에는 세 가지 일반적인 판별자가 있습니다. 즉, 이미지 단위 판별자, 패치 단위 판별자 및 픽셀 단위 판별자입니다. 특히 이미지 단위 판별자는 전역 분포에서 실제/가짜 이미지를 구별하도록 하는 것입니다. 그러나 이미지 단위 분포는 너무 거칠어서 네트워크가 이상적이지 않은 지역적 텍스처를 생성하게 합니다.
지역적인 질감을 향상시키기 위해 [45, 67, 68]은 패치 단위 판별자를 사용하여 패치 단위 분포를 결정하고 다양한 크기의 수용 영역으로 패치 크기를 조정합니다. 더 나아가, 픽셀 단위 판별자 [57]는 픽셀 단위로 실제/가짜 분포를 구별하면서 큰 계산 비용을 발생시킵니다. 그러나 위의 작업들은 하나의 이미지의 질감이 해당 이미지의 의미 분포를 충족해야 한다는 사실을 무시합니다. SR을 위해 미세한 의미 인식 질감을 달성하는 것이 필요합니다.
의미 인식 질감을 생성하기 위한 직관적인 방법 중 하나는 이미지의 의미를 생성기에 통합하는 것입니다. 이는 생성기에 의미 적응 기능을 부여합니다. 실제로 이는 의미 인식 질감 생성에 두 가지 명백한 단점을 가져옵니다: 1) 저품질 이미지는 더 나빠지고 심지어 오류가 있는 의미 추출을 낳을 수 있으며 합리적인 질감 생성을 방해합니다. 2) 추론 단계에서 복잡한 의미 추출기는 SR 네트워크의 계산 및 모델 복잡성의 비극적인 증가를 초래할 수 있습니다. 대조적으로, 우리는 다른 관점에서 SR을 위한 의미 인식 질감 생성을 달성하고자 합니다. 이 관점은 판별자입니다.
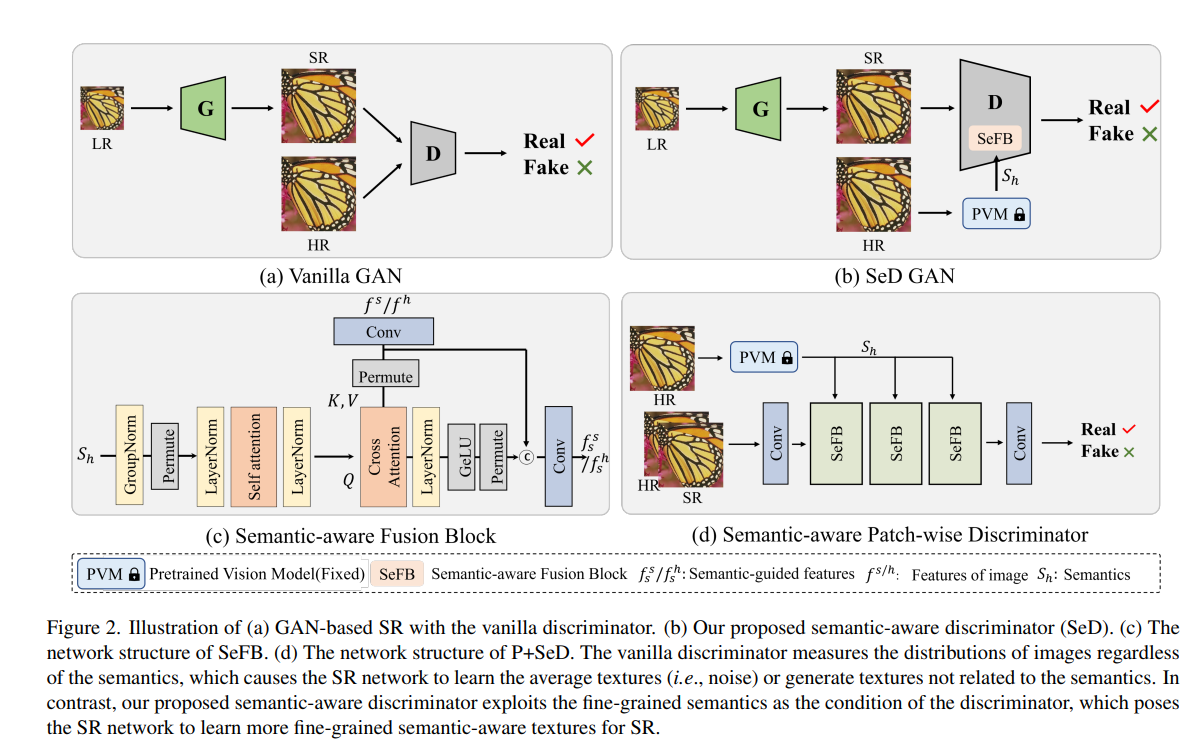
이 논문에서는 우리는 이미지 초고해상도(SR)를 위한 첫 번째 의미 인식 판별자인 SeD를 제안합니다. 이는 [81]에서 영감을 받았습니다. 판별자는 이미지/패치/픽셀이 실제인지 가짜인지 구별하는 방식으로 작동합니다. 적대적 훈련을 통해 생성된 이미지와 참조 이미지 간의 분포 거리를 측정할 수 있도록 합니다. 그림 1에서 보듯이 기본 판별자는 분포 거리만 측정하고 의미를 무시합니다. 이는 거친 평균 질감 (예: 노이즈)에 민감하게 반응합니다.
이를 완화하기 위해 최근 인기 있는 사전 훈련된 비전 모델(PVMs) (예: ResNet50 또는 CLIP)에서 추출한 의미를 판별자의 조건으로 도입합니다. 이를 통해 판별자는 다양한 의미에 대해 개별적으로 적응적으로 분포 거리를 측정할 수 있습니다 (그림 1(b) 참조). 의미 인식 판별자의 제약 하에서 SR 네트워크(즉, 생성기)는 더 세밀한 의미 인식 질감을 달성할 수 있습니다. 의미 인식 판별자를 달성하기 위한 중요한 단계는 의미를 추출하고 판별자에 통합하는 방법입니다. 단순한 전략은 사전 훈련된 분류 네트워크의 마지막 레이어 특성을 의미로 직접 도입하고 조건으로 판별자에 연결하는 것입니다. 그러나 이는 판별자에 효과적인 의미 안내를 방해하며 SR의 특성을 고려하지 않습니다.
세밀한 의미 인식 질감 생성을 달성하기 위해 한 가지 직관적인 방법은 서로 다른 영역의 의미가 다를 수 있으므로 의미는 픽셀 단위로 필요하다는 것입니다. 이를 고려하여 우리는 PVMs의 중간 특성에서 의미를 추출합니다. 이와 별도로, 우리는 의미를 판별자에 더 잘 통합하기 위해 의미 인식 퓨전 블록(SeFB)을 설계했습니다. 구체적으로 SeFB에서는 PVMs에서 추출한 의미를 쿼리로 간주하여 교차 주의를 통해 의미 인식 이미지 특성을 판별자에 전달합니다. 이를 통해 더 나은 의미 안내를 제공합니다. 우리는 제안된 SeD의 효과를 SR의 두 가지 전형적인 작업인 고전적인 SR 및 실제 이미지 SR 작업에서 검증했습니다. 또한, 우리의 SeD는 ESRGAN [65], RealESRGAN [66], BSRGAN [77]과 같은 다양한 GAN 기반 SR 벤치마크에 적용 가능하며 플러그 앤 플레이 방식으로 쉽게 통합할 수 있습니다.
본 논문의 기여는 다음과 같이 요약할 수 있습니다:
• SR을 위한 미세한 의미론적 질감 생성의 중요성을 강조하고, 최초로 PVMs에서 추출된 의미를 감별자에 통합하여 SR 작업을 위한 의미론적 감별자(SeD)를 제안합니다.
• 감별자에 대한 의미적 안내를 더 잘 통합하기 위해, 의미론적 퓨전 블록(SeFB)을 SeD에 제안합니다. 이는 픽셀 단위의 의미를 추출하고 교차-주의 방식으로 의미론적 이미지 피처를 감별자에 적용합니다.
• 클래식 및 실세계 이미지 SR 작업에 대한 방대한 실험 결과, 우리가 제안한 SeD의 효과를 확인했습니다. 또한, 우리의 SeD는 GAN 기반 SR 방법의 다양한 벤치마크에 쉽게 통합될 수 있습니다.
[Method]
기존의 많이 사용되는 Discriminator의 개념을 사용하지 않고 'Semantic-aware Discriminator'을 사용했습니다.
이를 통해서 이미지가 단순히 시각적으로 유사한 것뿐 아니라 의미적으로도 실제 이미지와 일치하는지를 평가합니다. 이러한 'Semantic-aware Discriminator'를 도입함으로써, 생성된 이미지의 질을 더욱 정교하게 평가할 수 있게 되었습니다.
'시맨틱 발굴'은 성공적인 시맨틱 인식 판별자를 위한 필수적인 요소입니다. 사전 훈련된 CLIP "RN50" 모델을 시맨틱 추출기로 사용하여 픽셀별 시맨틱 정보를 확보합니다. 실험 결과, 세 번째 레이어의 시맨틱 특징이 최적임이 확인되었습니다.
"나머지 내용은 모듈 설명과 아키텍처 설명인데 코드를 보면서 현재 회사에서 만들고 있는 모델에 접목할 계획"
[Conclusion]
본 논문에서는 이미지 초해상도를 위한 간단하지만 효과적인 시맨틱 인식 판별자(SeD)를 제안합니다. 이전 판별자들의 분포 학습이 지나치게 곡선으로 인해 가상이거나 직관에 반하는 질감을 유발한다는 것을 발견했습니다. 이를 완화하기 위해 사전 훈련된 비전 모델(PVMs)에서 이미지의 의미를 판별자의 조건으로 도입하고, 제안된 시맨틱 인식 퓨전 블록(SeFB)을 사용하여 세부적인 의미 인식 질감을 학습할 수 있도록 합니다. 또한, 우리의 SeD는 대부분의 GAN 기반 SR 방법에 쉽게 통합될 수 있으며 우수한 성능을 달성합니다. 고전적인 SR 및 현실 세계 SR에 대한 광범위한 실험에서 우리의 SeD의 효과를 입증했습니다.




댓글