논문 원본: https://arxiv.org/pdf/2006.12847

[Abstract]
- 이 논문에서는 cpu에서도 실시간으로 잘 작동하는 Sound Enhancement model을 제안했다.
- 모델의 아키텍처는 encoder-decoder, skip-connections으로 구성되어 있다.
- 위의 모델은 시간, 주파주 도메인에 최적화되며, 여러 손실 함수를 사용했다.
- 우리는 모델 성능과 일반화 능력을 더욱 향상시키기 위해 원시 파형(raw waveform)에 직접 적용되는 일련의 데이터 증강 기법을 제안함.
[Introduction]
- 우리는 실시간 버전의 'DEMUCS' 아키텍처를 제안했다.
- speech enhancement는 여러 개의 metrics이 존재하는데 인간의 평가와는 correlation이 크지 않다. 그래서 객관적, 주관적 평가를 모두 진행했다.
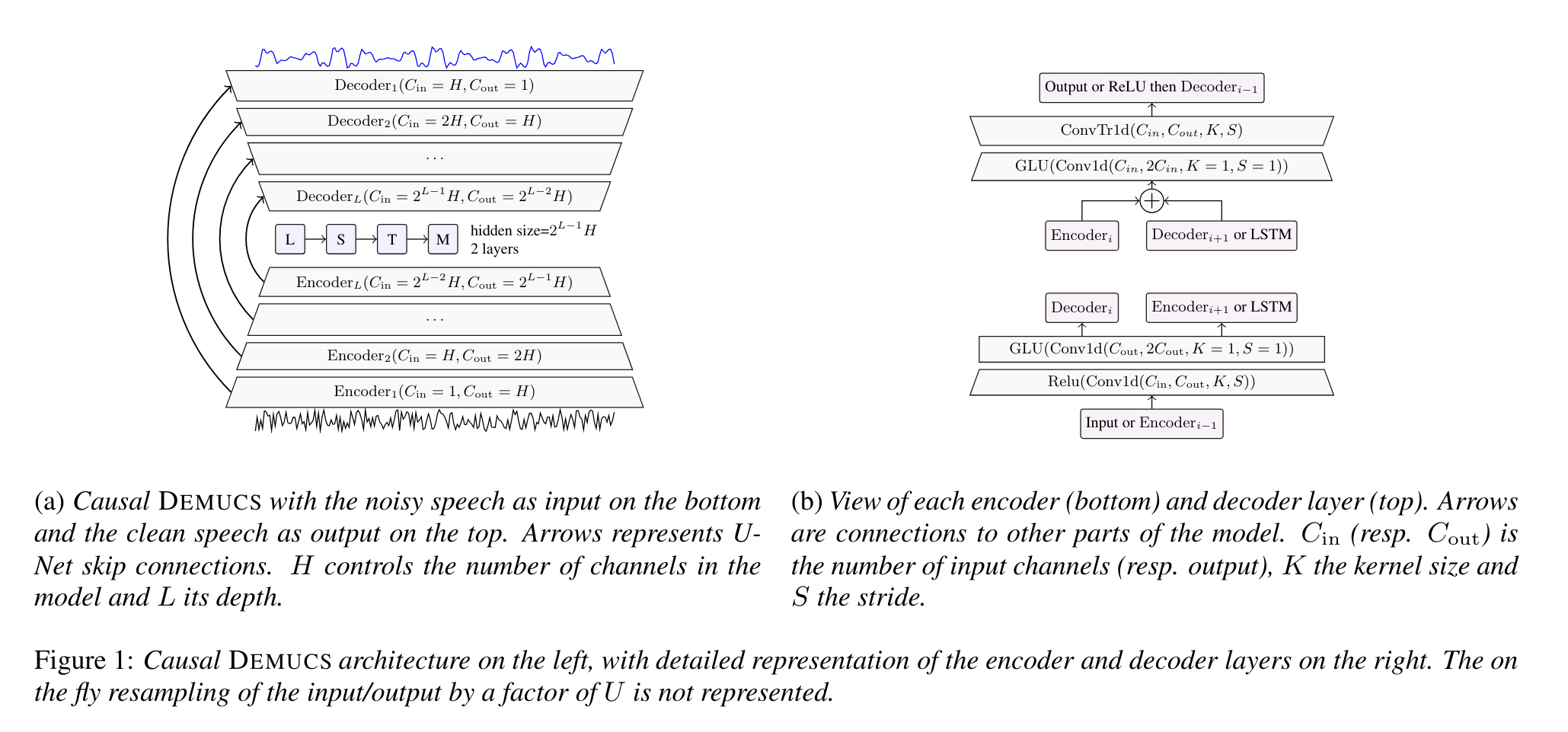
[Model]
- Notations and problem settings
(1) single-microphone(mono) speech enhancement에 집중함.
(2) x = y + n, y는 clean speech, n은 noise speech
(3) 우리는 f(x) ≈ y 인 함수를 찾는다!
(4) music source separation에 사용했던 DEMUCS 구조를 가져와서 사용한다.
- DEMUCS architecture
(1) multi-layer convolutional encoder and decoder와 U-net skip connections과 encoder 출력에 시퀀스 모델링 네트워크가 적용됨.
(2) 레이어수: L
채널 수: H
커널 크기: K
스트라이드: S
resampling factor: U
(3) 인코더와 디코더 레이어는 1부터 L까지 번호가 매겨집니다(디코더의 경우 반대 순서로 번호가 매겨지므로 같은 스케일의 레이어는 동일한 인덱스를 가집니다). 즉, encoder, decoder는 서로 대칭인 구조
(4) input, output은 single channel only
(5) seq2seq 구조이고, causal prediction에서는 unidirectional LSTM 사용하고 non causal models에서는 bidirectional LSTM 사용한다.
(6) encoder의 i-th layer 아웃풋과 decoder의 i-th layer 인풋을 skip connection으로 연결
(7) sinc interpolation filter로 resampling 했다.
- non causal DEMUCS: U=2, S=2, K=8, L=5 and H=64
- causal DEMUCS: U=4, S=4, K=8, L=5 and H=48 or H=64
- 모델에 주기 전에 표준 편차로 input을 normalizing하고, 아웃풋단에서 다시 원상복귀 하였다.
[Data augmentationPermalink]
(1) Remix augmentation
(2) 하나의 batch안에서 새로운 noisy 혼합물을 만들기 위해 noises를 섞는다.
(3) random shift 적용
(4) 0에서 S초 사이만큼
(5) BandMask
(6) mel scale에서 20%의 주파수 부분을 제거한다.
(7) SpecAug augmentation만 동일




댓글